摘要
ZeRO-Offload 主要优化在于尽量减少数据在 GPU 与 CPU 之间的移动,并减少 CPU 计算时间,同时最大限度地节省 GPU 上的内存。
原文链接:https://arxiv.org/pdf/2101.06840.pdf
开源代码:https://github.com/microsoft/deepspeed
背景
使用 Pytorch 训练内存不够,单个 V100 上性能为 30 TFlops
目前的分布式训练框架动辄需要超过 10w 刀的设备,难以在单卡上发挥作用
对于基于注意力机制的 LLM 训练,内存瓶颈主要在模型状态上
现有的异构训练方法主要利用 CPU 内存,而忽略了 CPU 的计算潜力
介绍
ZeRO-Offload 优化:尽量减少数据在 GPU 与 CPU 之间的移动,并减少 CPU 计算时间,同时最大限度地节省 GPU 上的内存
单个 V100 上性能提高到 40 TFlops,在 128 卡上实现接近线性加速,对比MP,模型规模增加了 4.5 倍
ZeRO-Offload 利用了CPU内存和计算资源进行 Offload,并与 ZeRO-DP 相结合
Efficiency
论文提出了一种名为Efficiency的offload策略,通过分析确定了CPU和GPU设备之间的最佳计算和数据划分策略,以在三个关键方面达到最优化:
- 在CPU上的计算量比GPU少多个数量级,防止CPU性能瓶颈;
- 最小化CPU和GPU之间的通信量,防止通信瓶颈;
- 在实现最小通信量的同时,可证明地最大化节约GPU内存。
分析表明,要在上述方面达到最优,必须将梯度、优化器状态和优化器计算卸载到CPU上,同时在 GPU 上保留参数、前向和反向计算。这种策略使模型规模增加了10倍,并且通信量最小。能够在一块 V100 GPU上训练130亿参数模型,性能为 40 TFLOPS,而没有 CPU offload 的情况下只能训练12亿参数模型,且性能只有30 TFLOPS。
offload 优化器计算要求CPU进行O(M)次计算,而GPU需进行O(MB)次计算,其中M和B分别为模型规模和 batch size 。在大多数情况下, batch size 较大,CPU计算量并不是瓶颈,但对于小 batch size,CPU计算量可能成为瓶颈。为了解决这个问题,采取了两种优化措施:
- 高效的CPU优化器,其速度比现有技术快6倍;
- 延迟一步的参数更新,允许将CPU优化器步骤与GPU计算重叠,同时确保准确性。这两种措施共同保证了ZeRO-Offload在小 batch size 下也能保持效率。
Unique Optimal Offload Strategy
为了确定最佳的下载策略,ZeRO-Offload将深度学习训练建模为数据流图,并使用基于第一原理的分析方法将该图分割为CPU和GPU设备之间的部分。
ZeRO-Offload 在以下三个关键方面优化了图的分割策略
- 要求更少数量级的CPU计算,以防止CPU成为性能瓶颈;
- 确保最小化CPU和GPU内存之间的通信量;
- 可证明地实现最小通信量的同时最大化内存节省。
训练的计算复杂度通常为O(MB),其中M为模型大小,B为有效batch size。为避免CPU计算成为瓶颈,只有那些计算复杂度低于O(MB)的计算才能转移到CPU上
FWD 和 BWD 的计算复杂度都是O(MB),必须在GPU上进行,而其余的计算,如范数计算、权重更新等,其复杂度为O(M),可以转移到CPU上
基于此,数据流图中的前向传播和反向传播节点合并为一个 FWD-BWD Super Node 并分配到 GPU 上
还需要最小化 CPU 与 GPU 的通信带宽,如图中所示,最小通信量为 BWD后 GPU 发送到 CPU 的 2M 梯度与 CPU 发送到 GPU 的 2M 参数,只有将 fp32 模型状态(momentum 32、variance 32和p32),Param Update 和 float2half 计算放置在一起,为一个 CPU 上的 Update Super Node,才能达成最小通信量策略
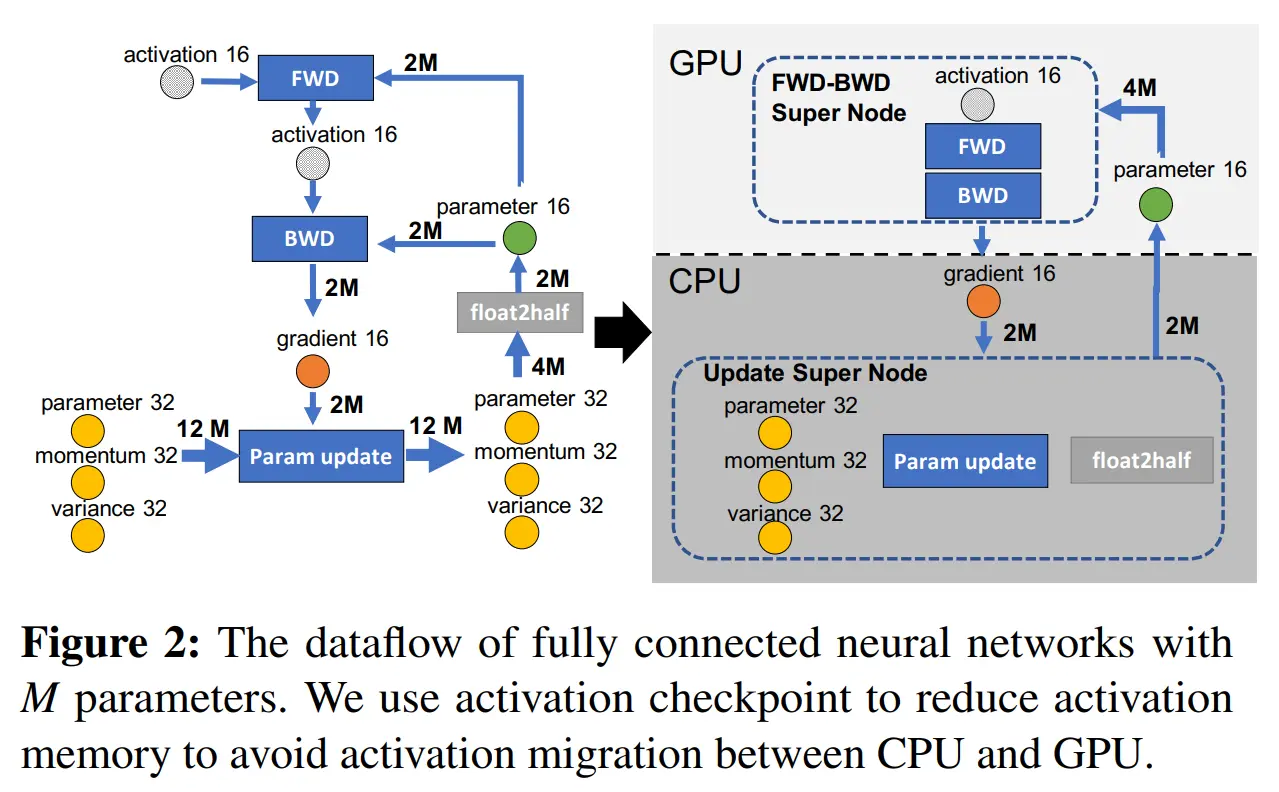
另外,上图中 2M 大小的 parameter 16 为什么分别到 FWD 与 BWD 有总和 4M 的数据传输,这个问题如有朋友知道,欢迎评论区讨论
实验依据如下
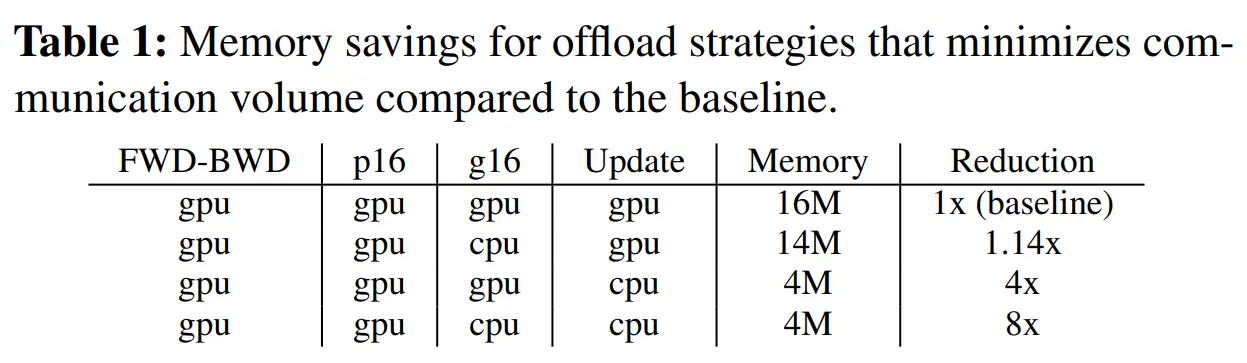
总之,ZeRO-Offload 策略就是将所有的 fp32 模型状态和 fp16 梯度存储在 CPU 内存中,并在 CPU 上计算参数更新。而 fp16 参数则保留在GPU上,前向和反向计算在GPU上进行
ZeRO-Offload Schedule
单卡策略
ZeRO-Offload将数据进行分区,将fp16参数存储在GPU上,fp16梯度和所有优化器状态(如fp32动量、方差和参数)存储在CPU上。
在训练过程中,首先通过 FWD 计算损失。由于fp16参数已经位于GPU上,因此这部分计算不需要与CPU进行通信。
在 BWD 过程中,不同参数的梯度在后向调度的不同位置计算。ZeRO-Offload可以立即将这些梯度逐个或切分传输到 CPU 内存中。
因此,在将梯度传输到CPU内存之前,只需要在GPU内存中临时保存少量的梯度。此外,每个梯度传输可以与反向计算重叠,消除大部分通信成本。
在 BWD 之后,ZeRO-Offload在CPU上直接更新fp32参数和剩余的优化器状态(如动量和方差),并将更新后的 fp32 参数从 CPU 内存复制到 GPU 内存中的fp16参数中。
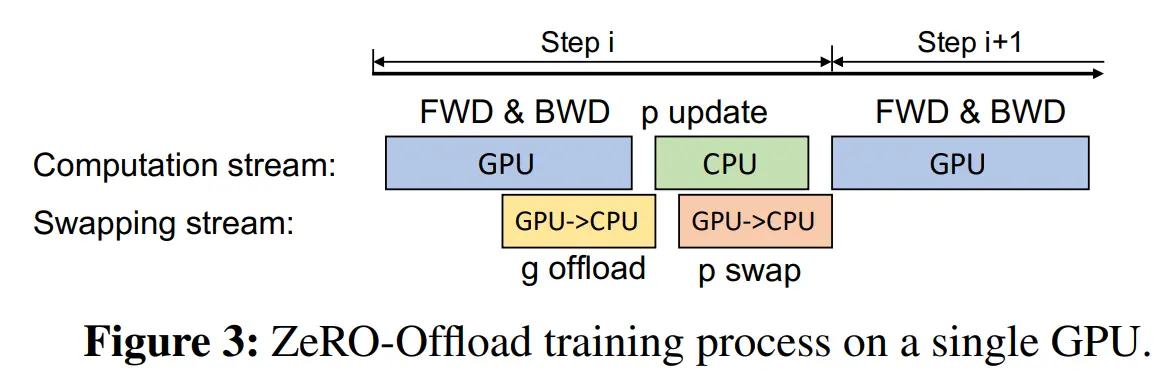
上图展示了 ZeRO-Offload 每个步骤中的计算通信过程,下图伪代码展示了具体的调度过程

多卡策略
ZeRO-Offload 将梯度和优化器状态在不同的 GPU 之间进行 partition,并且每个 GPU 将自己的 part offload 到 CPU 内存中,存储持续整个训练过程
BWD 过程中,在 GPU 上 reduce-scatter 计算梯度并平均,每个 GPU 仅将属于其 part 的平均梯度 offload 到 CPU 内存中
一旦梯度在 CPU 上可用,优化器状态 part 对应的每个 DP 进程直接在 CPU 上并行更新对应的参数 part
更新完成后,参数 part 发送到 GPU,在 GPU 上对参数进行类似 ZeRO-2 的 all-gather 操作
下面是 ZeRO-Offload 的多卡数据布局示意图
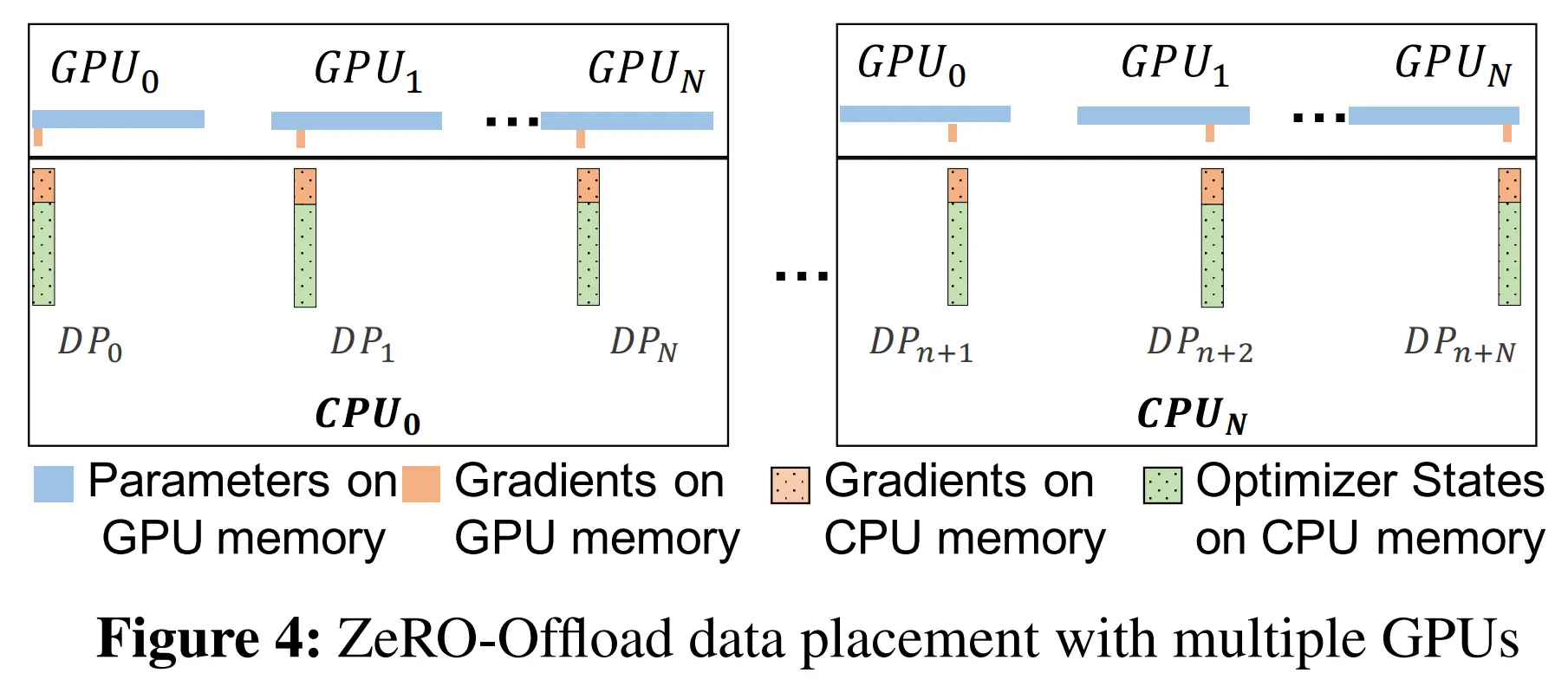
此外,ZeRO-Offload 还可以与 MP 和 Megatron-LM 同时使用,通过 offload MP 进程对应的梯度、优化器状态和优化器计算实现
Optimized CPU Execution
Implementing the CPU Optimizer
优化 CPU Optimizer 性能
- 使用SIMD向量指令
- 循环展开
- OMP 多线程并行计算
- 混合精度训练
在混合精度训练模式下,内存中的参数有两个版本
- FP32 版本,用于优化器在 CPU 上进行更新
- 浮点转换 FP32 后用于在 FWD 中计算激活的 FP16,用于GPU
此外,梯度的动量和方差也以 FP32 保存在 CPU 上,防止在更新参数时出现精度丢失
论文中的 adam 实现使用了 SIMD,通过将数据读入向量寄存器并使用多个融合乘加操作(FMA)构成主执行流水线,SIMD 矢量宽度由 simd_width 指定,并结合循环展开,自动调优的 unroll_width 为 8
同时,对计算的数据按 tile_width 分区,将 CPU上计算好的 FP32 数据 part 转换为 FP16 拷贝到 GPU 中,同时在 CPU 上计算下一个 数据 part,实现通信计算 overlap

One-Step Delayed Parameter Update(DPU)
在 DPU 训练过程中,首先在前 N-1 个步骤中进行训练,避免在训练的早期阶段梯度变化较快时破坏训练的稳定性。
在第N步,从 GPU 获取梯度,但跳过 CPU 优化器步骤,也不更新 GPU 上的 fp16 参数。
在第 N+1 步,使用第N步的梯度在CPU上计算参数更新,在GPU上并行计算前向和后向传播,使用第 N-1 步更新的参数。
从这一步开始,每个步骤的模型将使用从 i-1 步更新的参数进行训练,实现了 CPU 与 GPU 的计算重叠
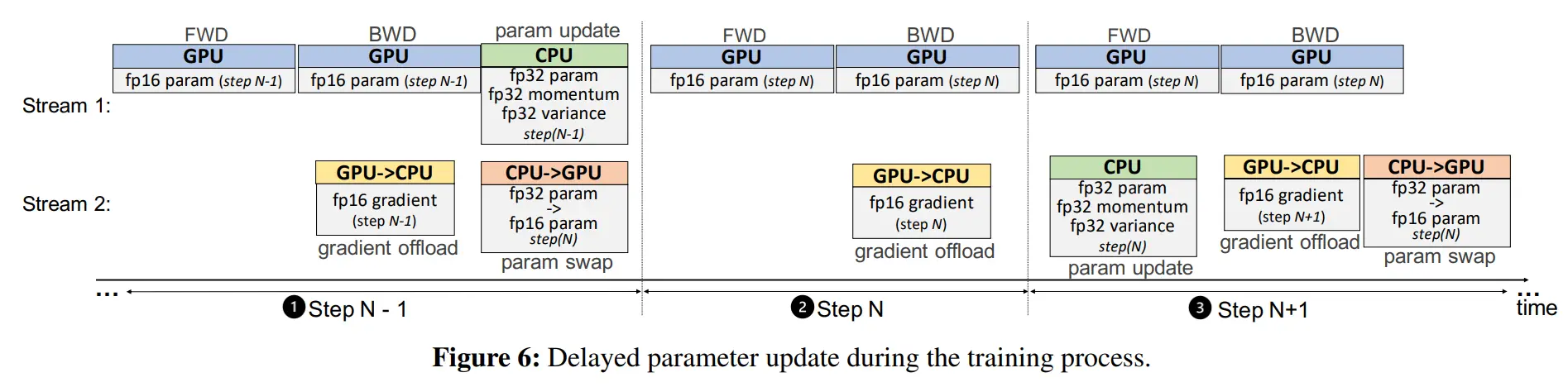
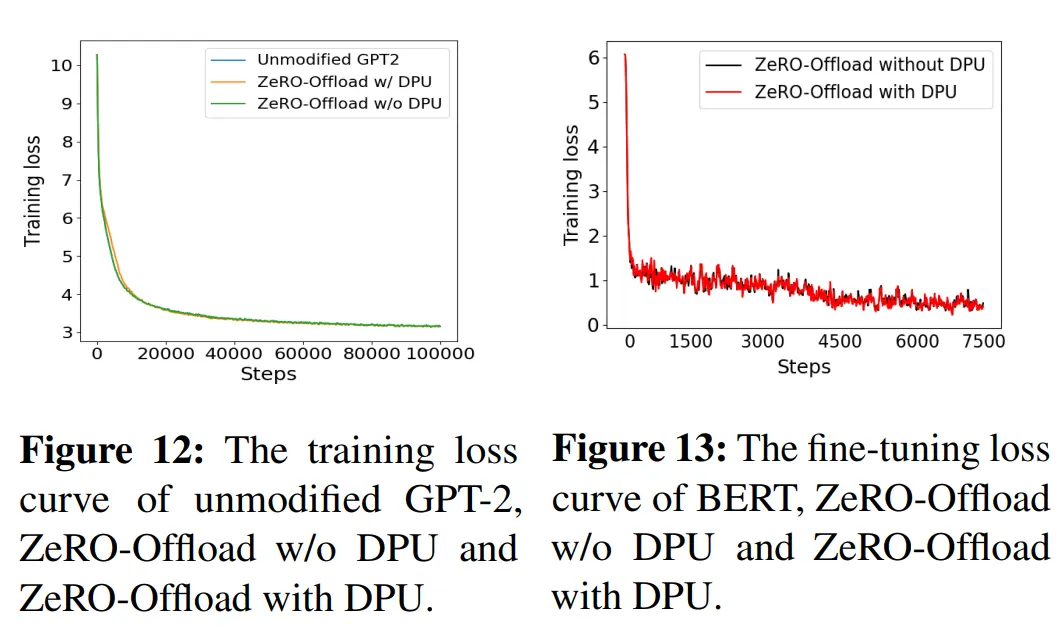
作者通过对多个训练工作评估发现,如果在几十次迭代之后引入 DPU,不会对收敛产生影响
实验
实验方法
硬件配置

实验模型:GPT-2、BERT
实验数据集:SQuAD
对比框架:PyTorch DDP、Megatron、L2L、ZeRO
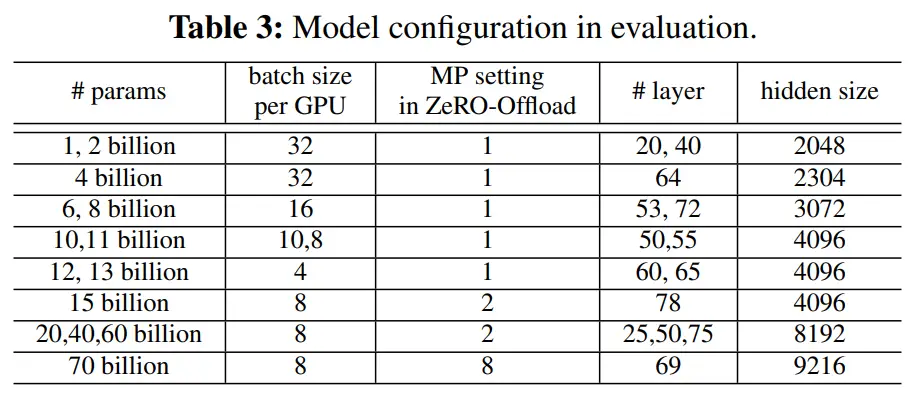
模型配置
实验结果
图7 在单个GPU,4个GPU和16个GPU(一个DGX-2节点)上可训练的最大模型参数量对比
图8 在 batch size 为 512 的单个GPU上使用 PyTorch,L2L 和 ZeRO-Offload 训练的 TFLOPS 对比
图9 使用 DPU 和不使用 DPU 的情况下,与 GPT-2 训练的 TFLOPS(batch_size = 8) 对比
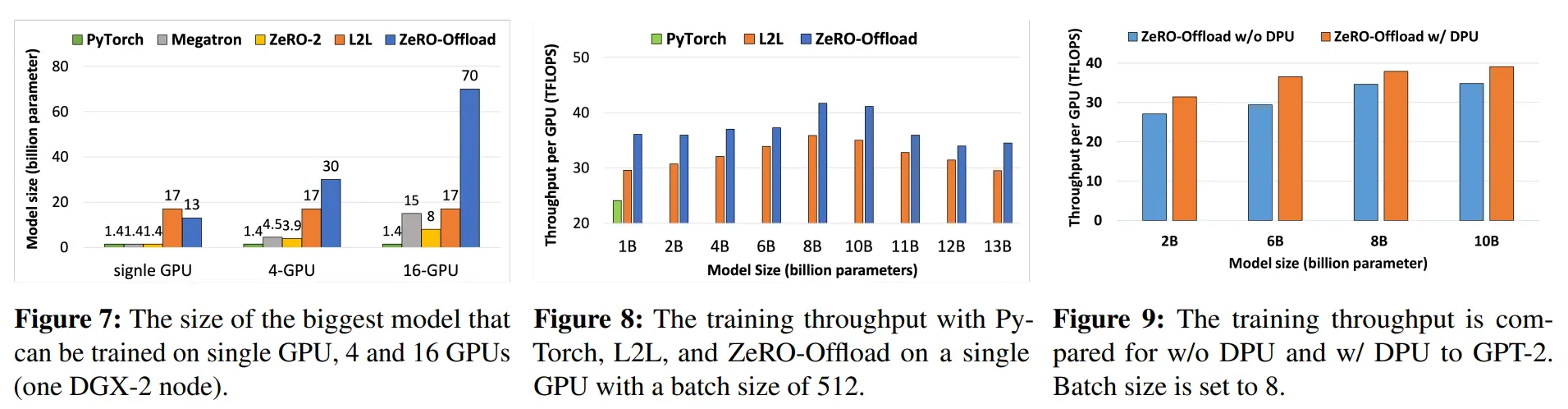
图10 针对不同模型大小,使用PyTorch、ZeRO-2、MegatronLM、ZeRO-Offload(无 MP)以及ZeRO-Offload(有 MP)训练的 TFLOPS 对比
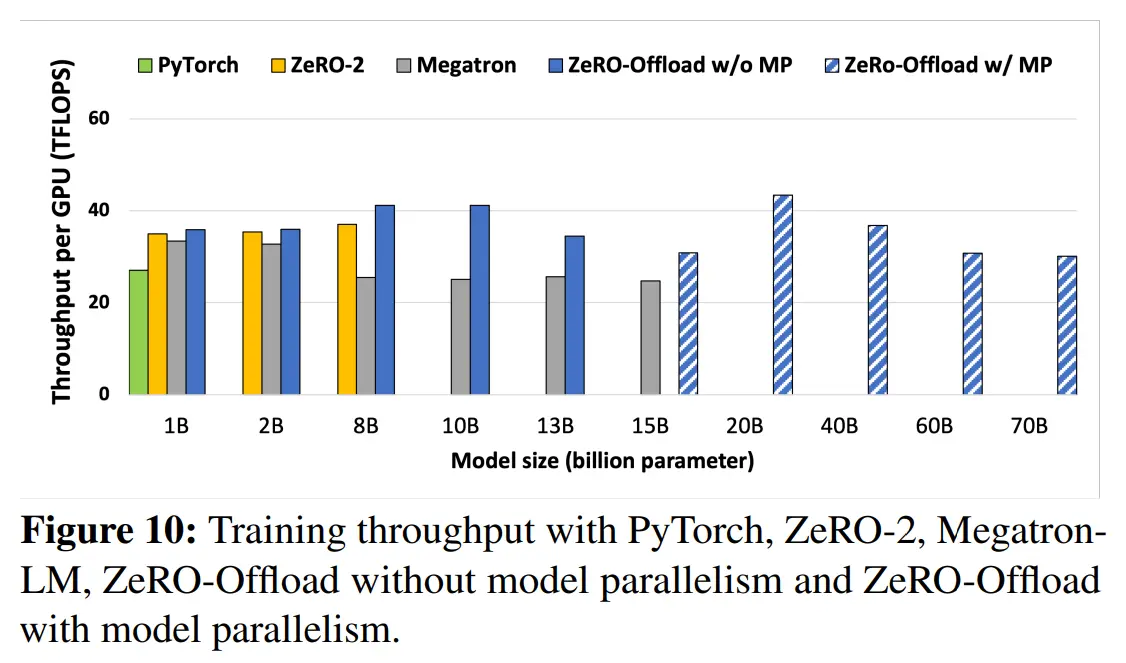
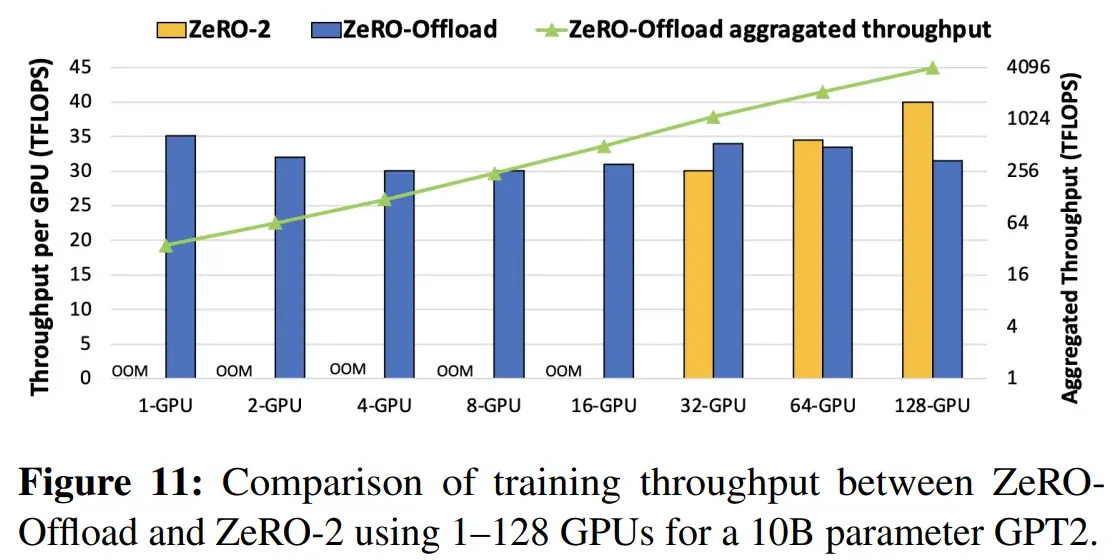
图11 针对不同 GPU 数量,ZeRO-2 和 ZeRO-Offload 的 TFLOPS 对比,从 64 卡开始 ZeRO-2 优于 ZeRO-Offload 是因为 ZeRO-2 没有 CPU-GPU 通信的额外开销
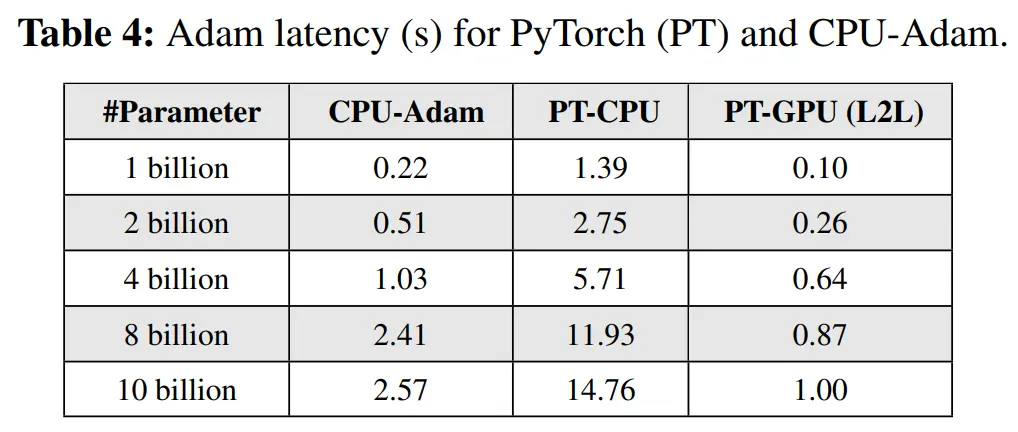
本文优化过的 CPU-Adam 与 PT-GPU 性能差距并不大,不会成为性能瓶颈
实验表明 DPU 策略在训练与微调上不会影响精度,最终的 F1 分数都是 0.92