摘要 深入介绍流的使用,包括流的并发,多线程调度流,并发限制,创建流间依赖关系,重叠主机与设备的执行等,同时,结合实例讲解了 CUDA 上下文以及 MPS 的概念,简单介绍了 CUDA Driver API 对 Context 的管理。
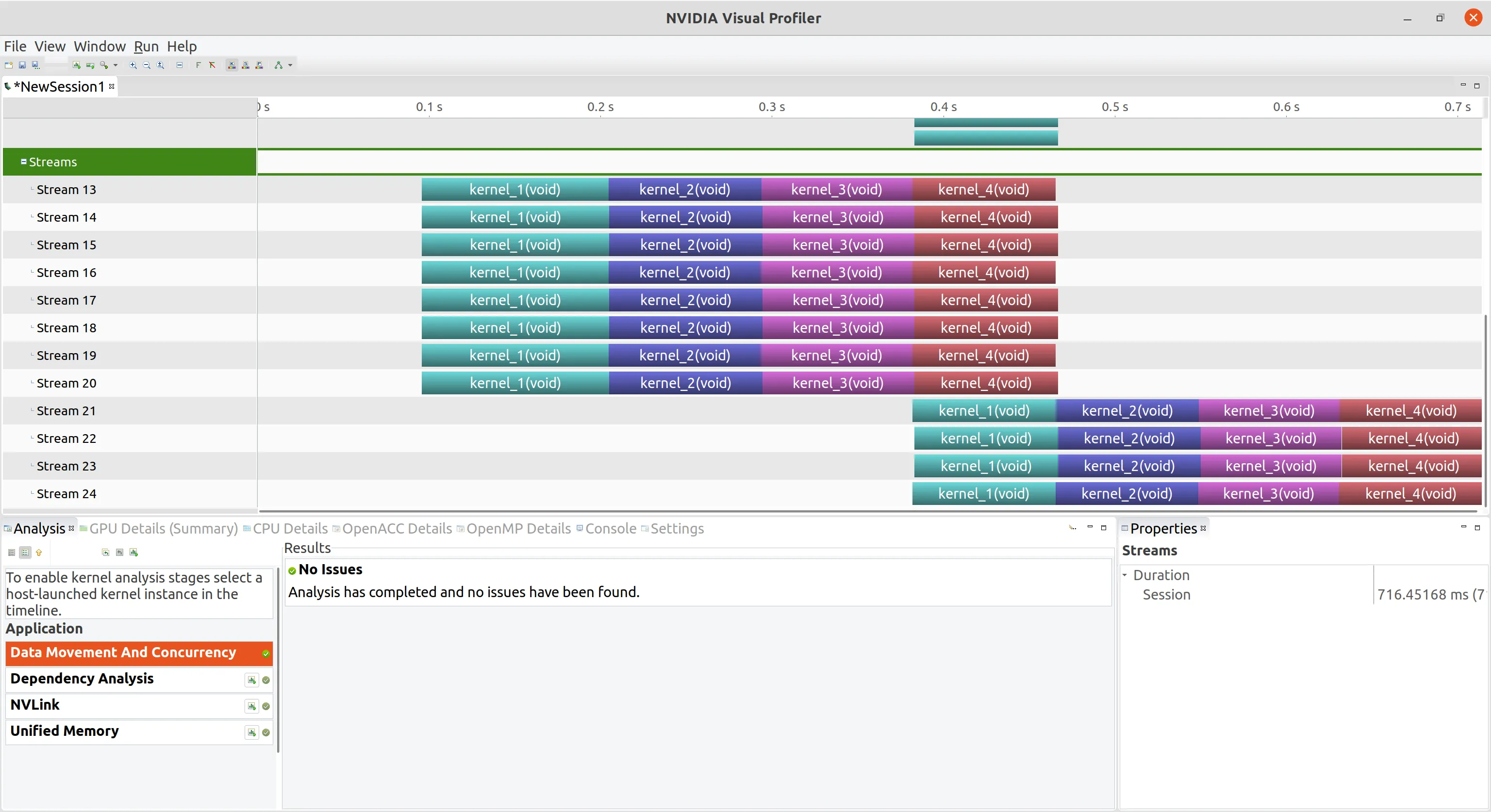
并发流的执行 非空流中的并发 以下面的核函数为例,定义一个非空流,将多个核函数加入到该流中。再循环定义多个流
注意核函数要足够复杂才能让非空流并行
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 #include <cuda_runtime.h> #include <stdio.h> __global__ void kernel_1 () { double sum=0.0 ; int tid = blockIdx.x * blockDim.x + threadIdx.x; double val = 0.1 + tid * 0.001 ; double res = 0.0 ; for (int i = 0 ; i < 1000000 ; i++) { res += tan (val) * tan (val); } sum += res; } __global__ void kernel_2 () { double sum=0.0 ; int tid = blockIdx.x * blockDim.x + threadIdx.x; double val = 0.1 + tid * 0.001 ; double res = 0.0 ; for (int i = 0 ; i < 1000000 ; i++) { res += tan (val) * tan (val); } sum += res; } __global__ void kernel_3 () { double sum=0.0 ; int tid = blockIdx.x * blockDim.x + threadIdx.x; double val = 0.1 + tid * 0.001 ; double res = 0.0 ; for (int i = 0 ; i < 1000000 ; i++) { res += tan (val) * tan (val); } sum += res; } __global__ void kernel_4 () { double sum=0.0 ; int tid = blockIdx.x * blockDim.x + threadIdx.x; double val = 0.1 + tid * 0.001 ; double res = 0.0 ; for (int i = 0 ; i < 1000000 ; i++) { res += tan (val) * tan (val); } sum += res; } int main () int n_stream=12 ; cudaStream_t *stream=(cudaStream_t*)malloc (n_stream*sizeof (cudaStream_t)); for (int i=0 ;i<n_stream;i++) { cudaStreamCreate (&stream[i]); } dim3 block (1 ) ; dim3 grid (1 ) ; cudaEvent_t start,stop; cudaEventCreate (&start); cudaEventCreate (&stop); cudaEventRecord (start,0 ); for (int i=0 ; i<n_stream; i++) { kernel_1<<<grid,block,0 ,stream[i]>>>(); kernel_2<<<grid,block,0 ,stream[i]>>>(); kernel_3<<<grid,block,0 ,stream[i]>>>(); kernel_4<<<grid,block,0 ,stream[i]>>>(); } for (int i=0 ;i<n_stream;i++) { cudaStreamSynchronize (stream[i]); } cudaEventRecord (stop,0 ); cudaEventSynchronize (stop); float elapsed_time; cudaEventElapsedTime (&elapsed_time,start,stop); printf ("elapsed time:%f ms\n" ,elapsed_time); for (int i=0 ;i<n_stream;i++) { cudaStreamDestroy (stream[i]); } cudaEventDestroy (start); cudaEventDestroy (stop); free (stream); return 0 ; }
这些内核启动的执行配置被指定为单一线程块中的单一线程,以保证有足够的 GPU 资源能并发运行所有的内核。因为每个内核启动相对主机来说都是异步的,所以可以通过使用单一主机线程同时调度多个内核到不同的流中
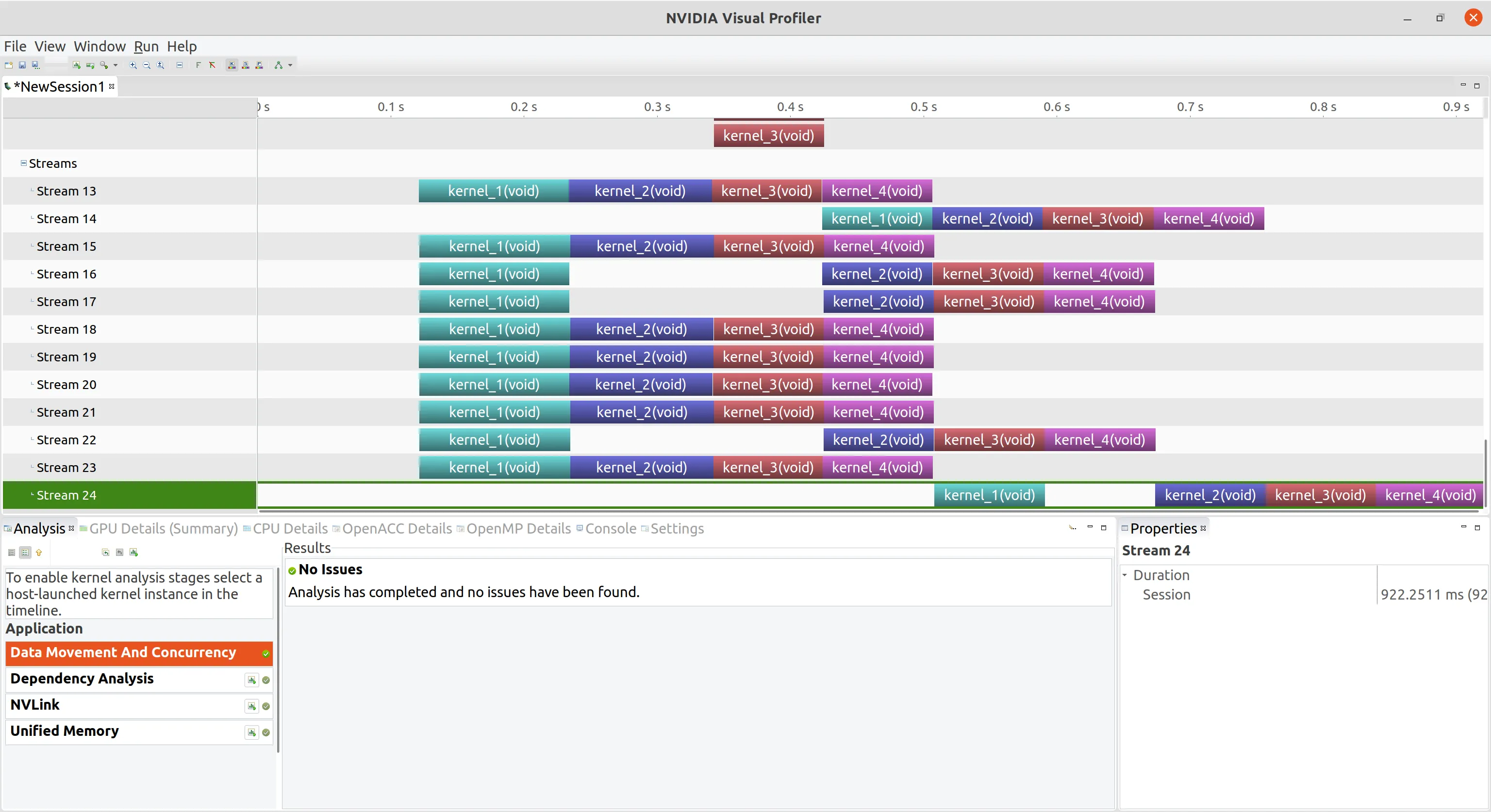
下图可以看到 12 个流以最大 8 个工作队列并行运行
使用 OpenMP 调度流 前面我们都是使用的单一主机线程调度流,我们可以在 CPU 上利用并行编程,使多个 CPU 线程管理多个流。这里,我们介绍一下,在 MPI (Message Passing Interface)、OpenMP 和 Pthread 这三种常见的 CPU 并行编程库:
MPI:MPI 是一种消息传递库,通常用于分布式内存环境中。MPI 库提供了一组函数,可以在多个计算节点之间发送和接收消息。通过使用 MPI,程序可以在多个计算节点上同时运行,从而实现并行计算 OpenMP:OpenMP 是一种共享内存并行编程库,它可以用于在单个计算节点的多个 CPU 核之间并行执行代码。OpenMP 提供了一组指令,可以将并行计算任务分配到不同的线程上执行。这些线程共享进程的内存空间,可以在程序的不同部分之间共享数据 Pthread:Pthread 是 POSIX 线程库的简称,也是一种共享内存并行编程库,与 OpenMP 类似,可以在单个计算节点上的多个 CPU 核之间并行执行代码。Pthread 提供了一组函数,用于创建和管理线程。这些线程共享进程的内存空间,可以在程序的不同部分之间共享数据 其中 OpenMP 的编译需要添加编译器预处理指令#pragma,创建线程等后续工作要编译器来完成。而 Pthread 所有的并行线程创建都需要我们自己完成,较 OpenMP 麻烦一点,但是更为灵活
所以我们下面学习使用 OpenMP 库同时调用多个线程,使用一个线程来管理每个流
1 2 3 4 5 6 7 8 9 10 11 #include <omp.h> omp_set_num_thread (n_stream);#pragma omp parallel { int i=omp_get_thread_num (); kernel_1<<<grid,block,0 ,stream[i]>>>(); kernel_2<<<grid,block,0 ,stream[i]>>>(); kernel_3<<<grid,block,0 ,stream[i]>>>(); kernel_4<<<grid,block,0 ,stream[i]>>>(); }
调用 OpenMP 的 API 创建 n_stream 个线程,#pragma omp parallel宏指令告诉编译器下面花括号中的部分就是每个线程都要执行的部分,括号中的部分可以称为并行单元
使用下面的命令使 nvcc 支持 OpenMP 指令编译
1 nvcc {}.cu -Xcompiler -fopenmp
关于 OpenMP 与 CUDA 之间更复杂的操作我们会在之后的文章和大家细细道来
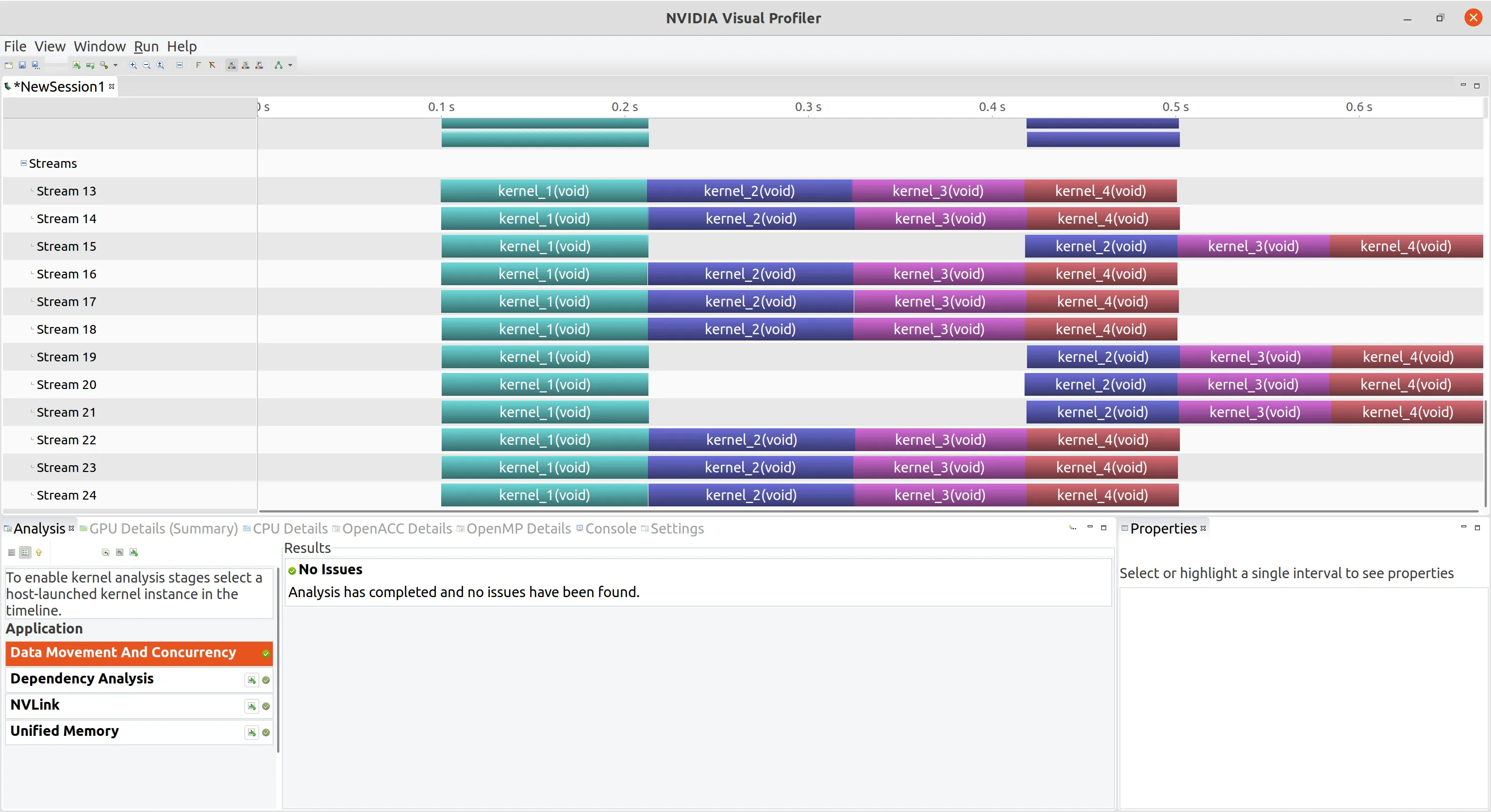
使用环境变量调整流行为 目前 Nvidia 支持的最大 Hyper-Q 工作队列数是 32,但是在默认情况下并不是全部开启,而是被限制成 8 个,原因是每个工作队列只要开启就会有资源消耗,如果用不到 32 个可以把资源留给需要的 8 个队列,修改这个配置的方法是修改主机系统的环境变量
对于Linux系统中,可以导入环境变量修改
1 export CUDA_DEVICE_MAX_CONNECTIONS=32
将 n_stream 改为 24,再次编译,下图可以看到并行工作队列数提高很多
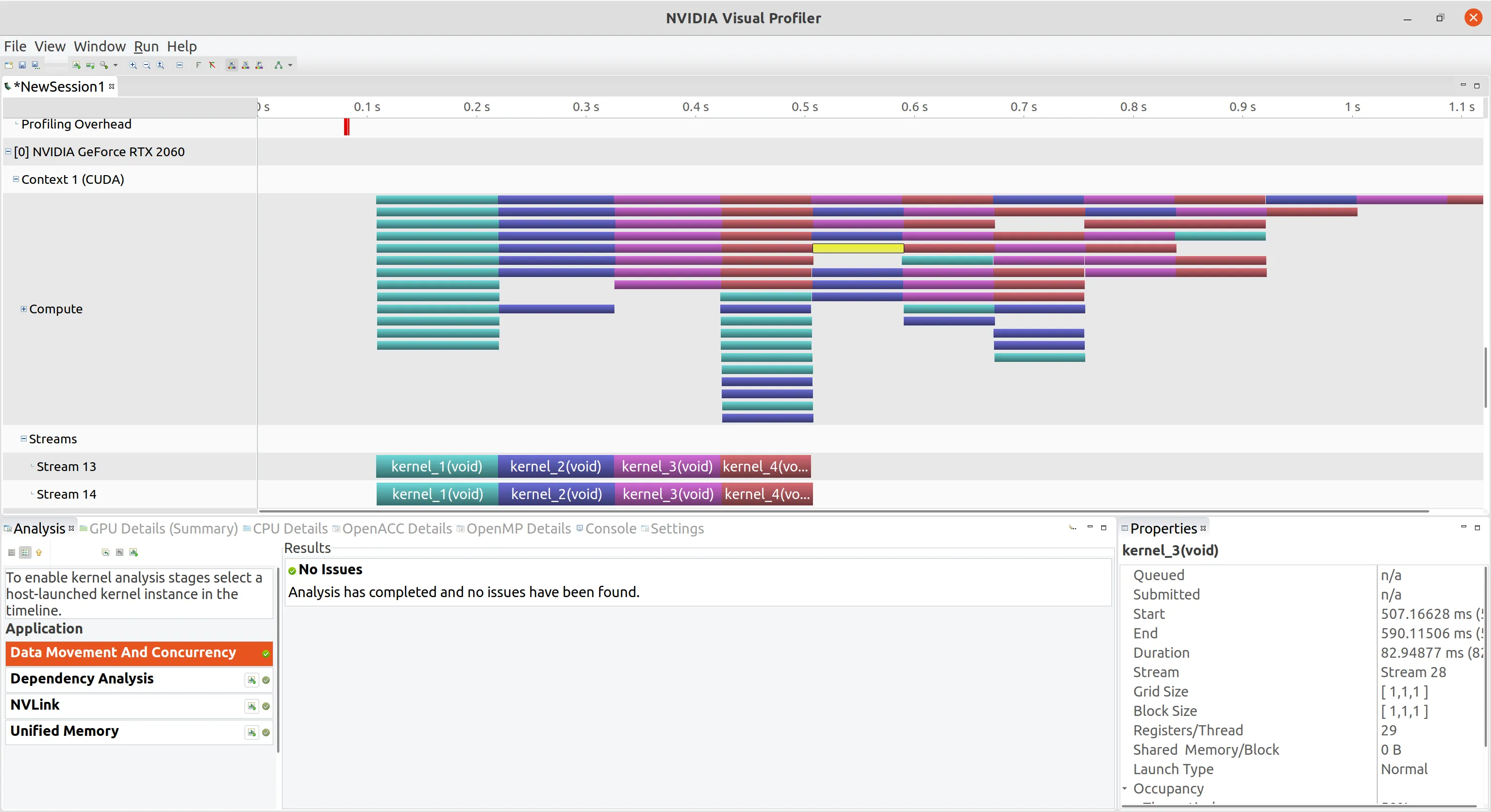
并发限制 有限的内核资源可以抑制应用程序中可能出现的内核并发的数量。在实际应用中,内核启动时通常会创建大量线程,这时,可用的硬件资源可能会成为并发的主要限制因素,因为它们阻止启动符合条件的内核。下面更改
1 2 dim3 block (1 ) ;dim3 grid (1 ) ;
为
1 2 dim3 block (16 ,32 ) ;dim3 grid (32 ) ;
将使用的 CUDA 流增加到 24,下图可以看到只实现了 4 路并发,因为 GPU 无法分配足够的资源,这里需要我们根据需求修改各个参数
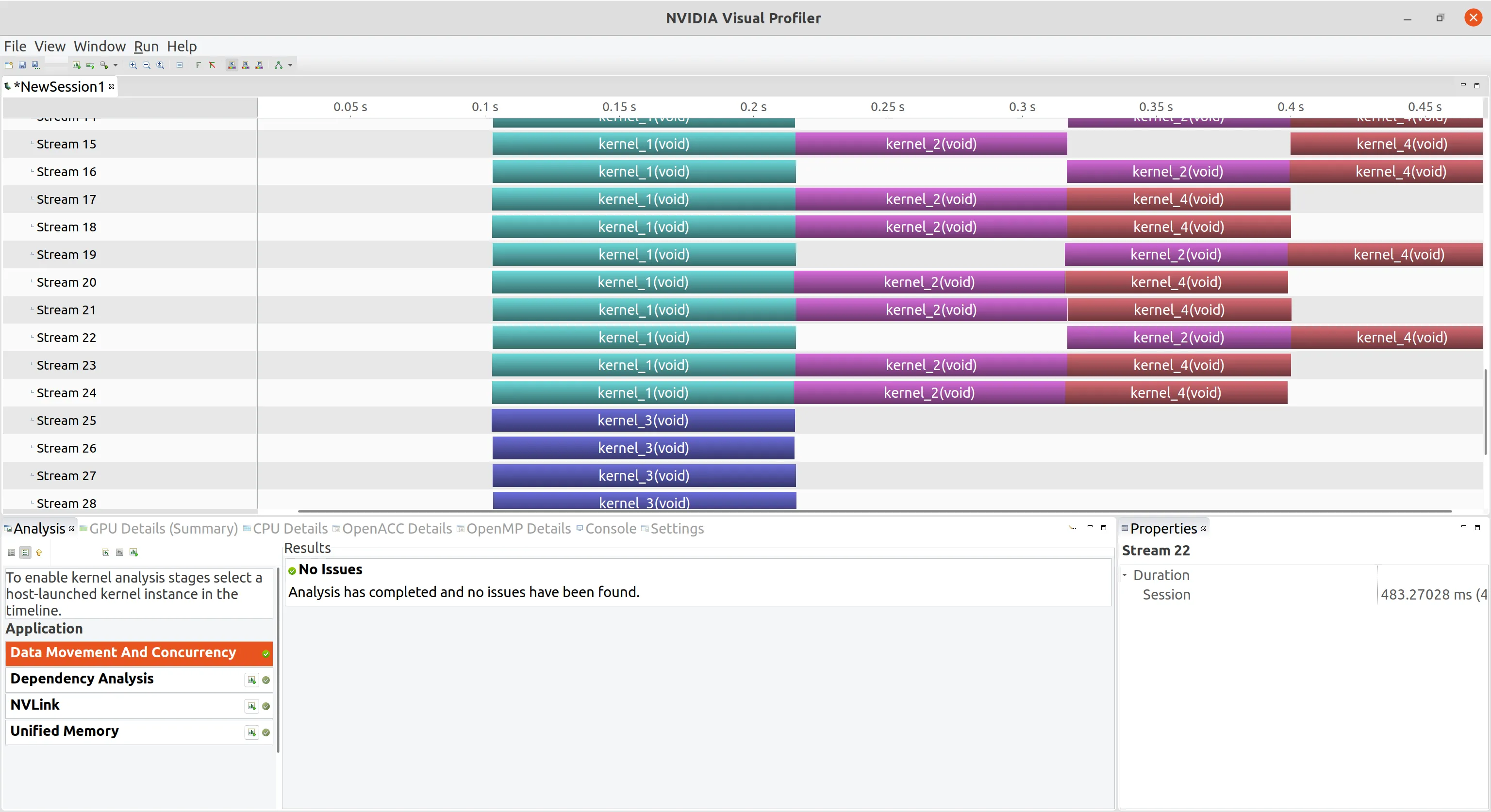
空流的阻塞行为 为了演示在空流中的的阻塞行为,将 n_stream 改回 12,block和grid改回1,我们将深度优先调度循环改为在空流的调用 kernel_3
1 2 3 4 5 6 for (int i=0 ;i<n_stream;i++) { kernel_1<<<grid,block,0 ,stream[i]>>>(); kernel_2<<<grid,block,0 ,stream[i]>>>(); kernel_3<<<grid,block>>>(); kernel_4<<<grid,block,0 ,stream[i]>>>(); }
可以看到所有 kernel_3 启动以后,所有其他的流中的操作全部被阻塞,空流对于非空流具有阻塞作用
创建流间依赖关系 理想情况下,流之间不应存在非预期的依赖关系(即虚假的依赖关系)。然而在实际使用时,我们需要一个流等待另一个流中的操作完成。可以使用事件在流之间创建依赖关系。首先,使用标志cudaEventDisableTiming创建同步事件
1 2 3 4 cudaEvent_t * event=(cudaEvent_t *)malloc (n_stream*sizeof (cudaEvent_t)); for (int i=0 ;i<n_stream;i++) { cudaEventCreateWithFlags (&event[i],cudaEventDisableTiming); }
接下来,使用cudaEventRecord在每个流完成时记录一个不同的事件,再使用cudaStreamWaitEvent来强制最后一个流(即流[n_streams-1])等待其他所有流
1 2 3 4 5 6 7 8 for (int i=0 ;i<n_stream;i++) { kernel_1<<<grid,block,0 ,stream[i]>>>(); kernel_2<<<grid,block,0 ,stream[i]>>>(); kernel_3<<<grid,block,0 ,stream[i]>>>(); kernel_4<<<grid,block,0 ,stream[i]>>>(); cudaEventRecord (event[i],stream[i]); cudaStreamWaitEvent (stream[n_stream-1 ],event[i],0 ); }
从下图的时间轴可以看到我们成功创建了流间的依赖关系,最后一个流会等到前面所有流中的事件完成,再运行
重叠内核执行和数据传输 前面的章节我们已经了解了数据传输队列(HtD, DtH),不是经过同一条队列的,这两个操作可以重叠完成,但是同向数据传输的时候不能进行此操作。此外,还需要检查数据传输和内核执行之间的关系:
如果内核使用数据 A,对 A 进行数据传输必须要在内核启动之前,且必须在同一个流中 如果内核不使用数据A,内核执行和数据传输可以位于不同的流中重叠执行 第二种情况就是重叠内核执行和数据传输的基本做法,当数据传输和内核执行被分配到不同的流中时,CUDA 执行的时候默认这是安全的,我们要保证它们之间的依赖关系。但是第一种情况也可以进行重叠,需要对核函数进行一定的分割,我们用向量加法核函数来举例
1 2 3 4 5 6 7 __global__ void ArraysSum (float *a, float *b, float *res, int N) { int idx = blockIdx.x*blockDim.x+threadIdx.x; if (idx < N) { for (int j=0 ;j<N_REPEAT;j++) res[idx]=a[idx]+b[idx]; } }
向量加法的过程是为
将两个输入向量从主机传入设备 内核计算结果 将结果从设备回传到主机 由于这个问题就是一个一步问题,我们没办法让内核和数据传输重叠,因为内核需要全部的数据,但是由于向量加法的每一位都互不干扰,我们可以把向量分块,并且每块中的数据只用于每块的内核,而跟其它分块的内核没有关系,这样就可以把整个过程分成 N_SEGMENT 份,也就是 N_SEGMENT 个流分别执行
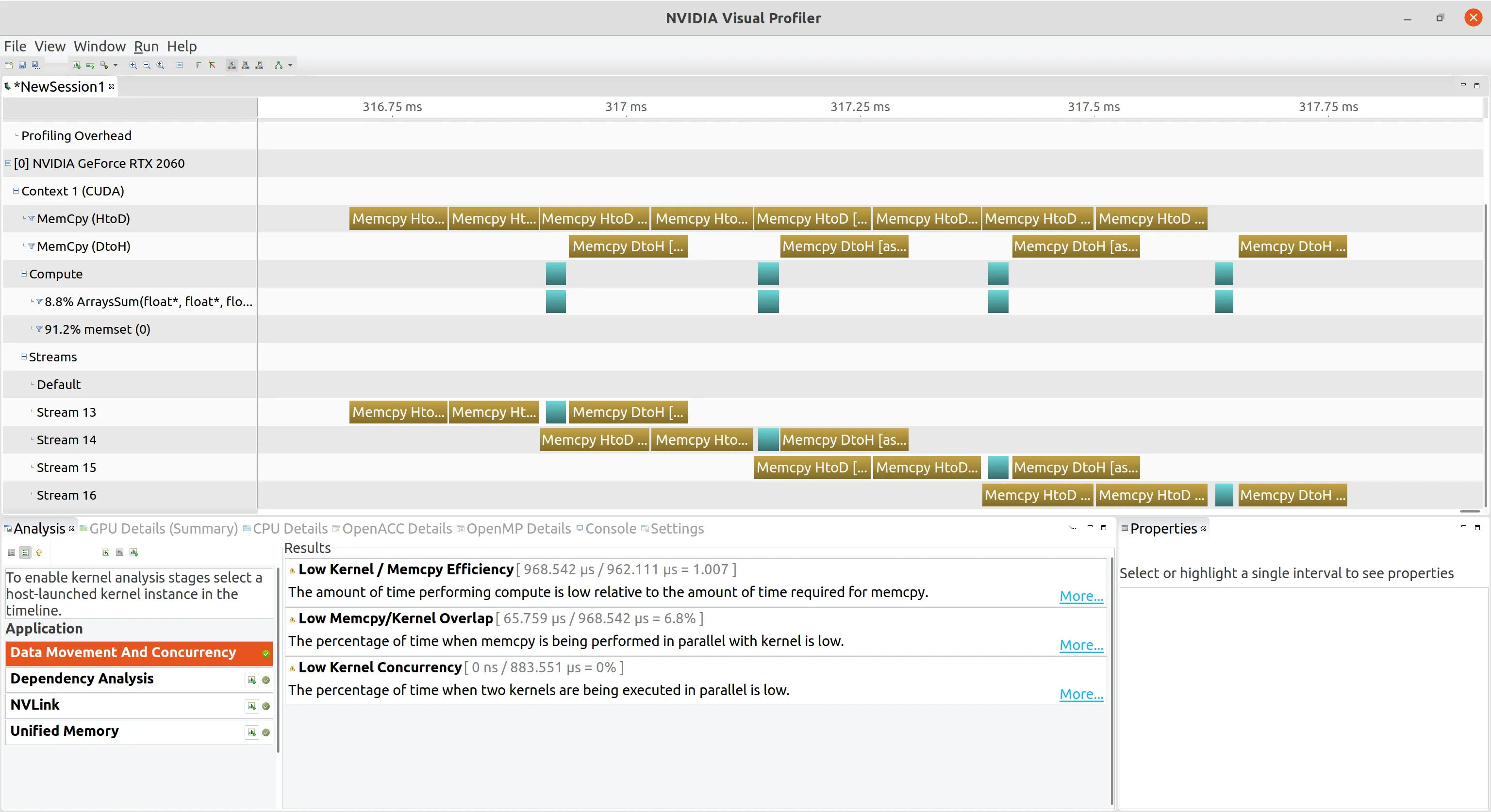
深度优先调度重叠 我们首先使用深度优先调度的方式。这里需要注意数据传输是异步的,所以必须声明为固定内存,不能是分页内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #include <cuda_runtime.h> #include <stdio.h> #define N_REPEAT 10 #define N_SEGMENT 4 __global__ void ArraysSum (float *a,float *b,float *res,int N) { int idx=blockIdx.x*blockDim.x+threadIdx.x; if (idx < N) { for (int j=0 ;j<N_REPEAT;j++) res[idx]=a[idx]+b[idx]; } } int main (int argc,char **argv) int nElem=1 <<20 ; printf ("Vector size:%d\n" ,nElem); int nByte=sizeof (float )*nElem; float * a_h,*b_h,*res_h,*res_from_gpu_h; cudaHostAlloc ((float **)&a_h,nByte,cudaHostAllocDefault); cudaHostAlloc ((float **)&b_h,nByte,cudaHostAllocDefault); cudaHostAlloc ((float **)&res_h,nByte,cudaHostAllocDefault); cudaHostAlloc ((float **)&res_from_gpu_h,nByte,cudaHostAllocDefault); cudaMemset (res_h,0 ,nByte); cudaMemset (res_from_gpu_h,0 ,nByte); float *a_d,*b_d,*res_d; cudaMalloc ((float **)&a_d,nByte); cudaMalloc ((float **)&b_d,nByte); cudaMalloc ((float **)&res_d,nByte); dim3 block (512 ) ; dim3 grid ((nElem-1 )/block.x+1 ) ; int iElem=nElem/N_SEGMENT; cudaStream_t stream[N_SEGMENT]; for (int i=0 ;i<N_SEGMENT;i++) { cudaStreamCreate (&stream[i]); } cudaEvent_t start,stop; cudaEventCreate (&start); cudaEventCreate (&stop); cudaEventRecord (start,0 ); for (int i=0 ;i<N_SEGMENT;i++) { int ioffset=i*iElem; cudaMemcpyAsync (&a_d[ioffset],&a_h[ioffset],nByte/N_SEGMENT,cudaMemcpyHostToDevice,stream[i]); cudaMemcpyAsync (&b_d[ioffset],&b_h[ioffset],nByte/N_SEGMENT,cudaMemcpyHostToDevice,stream[i]); ArraysSum<<<grid,block,0 ,stream[i]>>>(&a_d[ioffset],&b_d[ioffset],&res_d[ioffset],iElem); cudaMemcpyAsync (&res_from_gpu_h[ioffset],&res_d[ioffset],nByte/N_SEGMENT,cudaMemcpyDeviceToHost,stream[i]); } cudaEventRecord (stop, 0 ); for (int i=0 ;i<N_SEGMENT;i++) { cudaStreamDestroy (stream[i]); } cudaFree (a_d); cudaFree (b_d); cudaFree (a_h); cudaFree (b_h); cudaFree (res_h); cudaFree (res_from_gpu_h); cudaEventDestroy (start); cudaEventDestroy (stop); return 0 ; }
nvvp 可视化如下
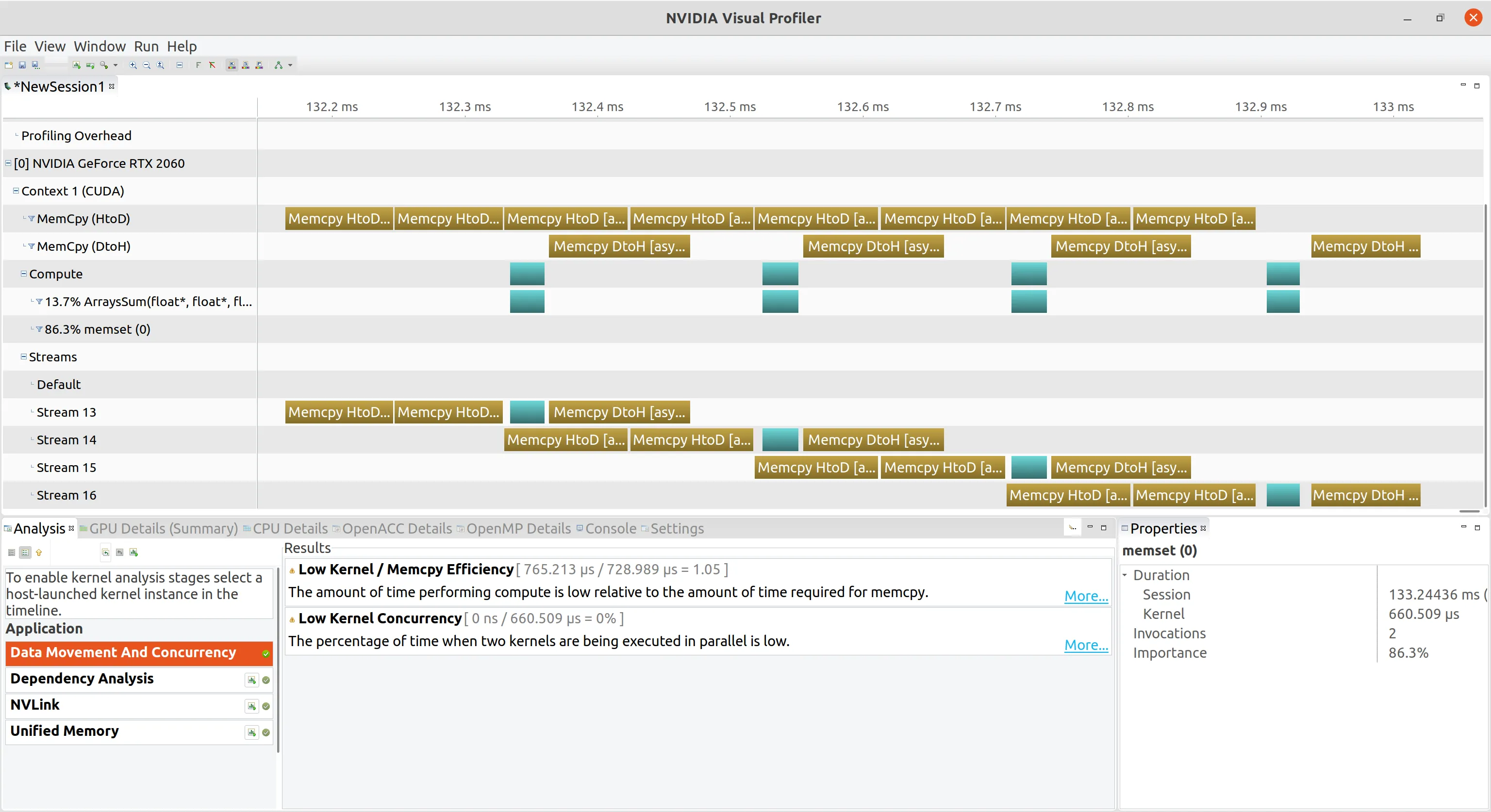
广度优先调度重叠 循环修改为如下代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 for (int i=0 ;i<N_SEGMENT;i++){ int ioffset=i*iElem; CHECK (cudaMemcpyAsync (&a_d[ioffset],&a_h[ioffset],nByte/N_SEGMENT,cudaMemcpyHostToDevice,stream[i])); CHECK (cudaMemcpyAsync (&b_d[ioffset],&b_h[ioffset],nByte/N_SEGMENT,cudaMemcpyHostToDevice,stream[i])); } for (int i=0 ;i<N_SEGMENT;i++){ int ioffset=i*iElem; ArraysSum<<<grid,block,0 ,stream[i]>>>(&a_d[ioffset],&b_d[ioffset],&res_d[ioffset],iElem); } for (int i=0 ;i<N_SEGMENT;i++){ int ioffset=i*iElem; CHECK (cudaMemcpyAsync (&res_from_gpu_h[ioffset],&res_d[ioffset],nByte/N_SEGMENT,cudaMemcpyDeviceToHost,stream[i])); }
nvvp 可视化和深度优先调度重叠一模一样,所以我们不需要关注深度还是广度的调度顺序
重叠主机与设备的执行 实现 GPU 和 CPU 的执行重合是相对直接的,因为所有的内核默认情况下是异步启动的。因此,只要启动一个内核,并立即在主机线程中实现有效操作,就会自动产生 GPU 和 CPU 执行的重叠
以下面的加法核函数为例
1 2 3 4 __global__ void kernel (float *g_data, float value) { int idx = blockIdx.x * blockDim.x + threadIdx.x; g_data[idx] = g_data[idx] + value; }
在这个例子中,有两个拷贝和一个内核启动操作,记录了一个停止事件,以标记所有 CUDA 操作的完成
1 2 3 4 cudaMemcpyAsync (d_a, h_a, nbytes, cudaMemcpyHostToDevice);kernel<<<grid, block>>>(d_a, value); cudaMemcpyAsync (h_a, d_a, nbytes, cudaMemcpyDeviceToHost);cudaEventRecord (stop);
这些操作与主机都是异步的,它们都被绑定到默认流中,一旦最后一个cudaMemcpyAsync被发出,控制权将立即返回到主机。一旦控制权返回给主机,主机就可以做任何不依赖内核输出的有用的计算。在下面的代码段中,主机只是简单地进行迭代,等待所有CUDA操作的完成,同时递增一个计数器。在每次迭代中,主机线程查询停止事件。一旦该事件满足,主机线程就会继续
1 2 3 4 5 6 7 8 9 10 int counter = 0 ;while (cudaEventQuery (stop) == cudaErrorNotReady) { counter++; } printf ("Counter: %ld\n" ,counter);
流回调 流回调是另一种可以到 CUDA 流排列等待的操作类型。 一旦流回调之前的流中的所有操作都已完成,CUDA 运行时将调用流回调指定的主机端函数,该函数由应用程序提供,这允许将任意主机端逻辑插入到 CUDA 流中。 流回调是另一种 CPU 到 GPU 同步机制,但是流回调时,回调函数中不可以调用 CUDA 的 API,且不可以执行同步
流函数有特殊的参数规格,必须写成下面形式参数的函数
1 2 3 void CUDART_CB my_callback (cudaStream_t stream, cudaError_t status, void *data) printf ("callback from stream %d\n" , *((int *)data)); }
该函数有三个参数:
cudaStream_t stream:表示回调函数与哪个CUDA流相关联。当流中的所有操作都完成时,CUDA运行时将调用此回调函数cudaError_t status:表示流中最后一个操作的状态。如果状态是cudaSuccess,则表示所有操作已成功完成void *data:表示传递给回调函数的数据指针。在此示例中,该指针指向一个整数,其中包含与流相关的自定义数据并使用下面的函数加入流中
1 cudaError_t cudaStreamAddCallback (cudaStream_t stream,cudaStreamCallback_t callback, void *userData, unsigned int flags) ;
stream:CUDA 流,表示将要添加回调函数的流callback:回调函数,该函数会在指定的流上的所有操作都已经完成时被调用。回调函数的原型为 void (*)(cudaStream_t, cudaError_t, void*),其中第一个参数表示回调函数所在的流,第二个参数表示流上的最后一个 CUDA 操作的状态,第三个参数为用户自定义数据userData:用户自定义数据指针,会在回调函数被调用时传递给回调函数flags:标志位,用于控制回调函数的行为。目前只支持 cudaStreamCallbackBlocking 和 cudaStreamCallbackNonblocking 两种标志位,分别表示回调函数是阻塞还是非阻塞的。如果使用阻塞回调函数,则该回调函数必须在流上的所有操作完成后才能被调用。如果使用非阻塞回调函数,则该回调函数可能会在流上的操作尚未全部完成时被调用下面是流回调的一个例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void CUDART_CB my_callback (cudaStream_t stream,cudaError_t status,void * data) printf ("call back from stream:%d\n" ,*((int *)data)); } int main (int argc,char **argv) for (int i=0 ;i<N_SEGMENT;i++) { int ioffset=i*iElem; cudaMemcpyAsync (&a_d[ioffset],&a_h[ioffset],nByte/N_SEGMENT,cudaMemcpyHostToDevice,stream[i]); cudaMemcpyAsync (&b_d[ioffset],&b_h[ioffset],nByte/N_SEGMENT,cudaMemcpyHostToDevice,stream[i]); ArraysSum<<<grid,block,0 ,stream[i]>>>(&a_d[ioffset],&b_d[ioffset],&res_d[ioffset],iElem); cudaMemcpyAsync (&res_from_gpu_h[ioffset],&res_d[ioffset],nByte/N_SEGMENT,cudaMemcpyDeviceToHost,stream[i]); cudaStreamAddCallback (stream[i],my_callback,(void *)(stream+i),0 ); }
CUDA Context 上下文 CUDA Context 是一个由特定进程与设备相关联的状态集合,包括:
CUDA 程序通过使用 CUDA Context 来管理设备资源和执行 CUDA 指令。每个进程可以有多个 CUDA Context,每个 CUDA Context 只能与一个设备相关联。CUDA 程序通过使用 CUDA Context 来管理设备资源和执行 CUDA 指令
每个进程或 GPU 可以有多个 CUDA Context,而每个 CUDA Context 只能与一个 GPU 相关联
在 CUDA 中,每个任务都有一个独立的设备 ID,每个设备 ID 对应一个唯一的 CUDA Context。所以 Context 类似于 CPU 上的进程,由 Driver 层管理分配资源的生命周期
与 CPU 进程的管理类似,每个 Context 有自己的地址空间,且之间是隔离的,在一个 Context 中所有指针只能在这一个 Context 中使用,但一个 CUDA Context 中的任何一个 kernel 被挂掉后,则此时处于同一个 GPU 上的 所有 Context 的所有都会失效
隐式创建 CUDA Runtime 软件层的库是隐式创建 context,且不提供 API 直接创建 CUDA context,而是通过延迟初始化(deferred initialization)来创建 context,也就是 lazy initialization
在 Linux 中通过导入环境变量延迟初始化
1 export CUDA_MODULE_LOADING=LAZY
CUDA_MODULE_LOADING 默认为 EAGER,会最大限度地减少模块加载时的延迟,但会增加程序启动时间和内存占用
具体意思是在调用每一个 CUDART 库函数时,它会检查当前是否有 context 存在,假如需要 context,那么才自动创建。也就是说需要创建上面这些对象的时候就会创建context。可以显式的控制初始化,即调用 cudaFree(0),强制的初始化
CUDA Runtime 将 context 和 device 的概念合并了,即在一个 GPU 上操作可看成在一个 context 下
显示创建 可以使用 CUDA Driver API 显示创建 context,CUDA Driver API 是一种更偏向底层的 API,提供了对硬件的更细粒度的控制,直接控制 GPU 的所有硬件资源。这些函数被实现在 CUDA Driver 库 中,需要手动链接这个库并直接调用这些函数,下面几个函数用于管理 CUDA 上下文
1 CUresult cuCreateContext (CUcontext* pctx, unsigned int flags, CUdevice dev) ;
创建 CUDA 上下文
pctx:输出参数,指向新创建的CUDA上下文句柄
flags:用于设置上下文属性的标志位,可以为 0
dev:用于创建上下文的设备句柄
返回 CUDA_SUCCESS 表示函数调用成功,否则返回错误码
1 CUresult cuPushCurrent (CUcontext ctx) ;
将当前线程的CUDA上下文压入上下文栈中,并将给定上下文设置为当前上下文
ctx:要设置为当前上下文的CUDA上下文句柄 返回 CUDA_SUCCESS 表示函数调用成功,否则返回错误码 1 CUresult cuPopCurrent (CUcontext *pctx) ;
将当前线程的CUDA上下文从上下文栈中弹出,并将上下文栈顶的上下文设置为当前上下文
pctx:输出参数,指向弹出的CUDA上下文句柄 返回 CUDA_SUCCESS 表示函数调用成功,否则返回错误码 其中,隐式调用的context是 primary context,由 CUDA 驱动程序自动创建和管理; 显示调用的 context 是standard context,需要手动管理其生命周期和状态,并且可以同时存在多个 standard context。每次 CUDA 初始化比较费时间,可能是 Runtime 进行了隐式调用 context,可以使用 cudaError_t cudaSetDevice(int device) 提前创建 context 节省这部分时间
使用 CUDA Driver API 编写的 CUDA 程序通常具有更高的性能,因为它们可以更充分地利用 GPU 的硬件资源。但是,由于这种API需要我们对硬件有更深入的了解,并且需要编写更多的底层代码,所以这种编程方式会更加困难和容易出错,目前阶段我们暂不深入了解这个库,下面只给出简单示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 #include <cuda.h> #include <stdio.h> #include <string.h> #define checkDriver(op) __check_cuda_driver((op), #op, __FILE__, __LINE__) bool __check_cuda_driver(CUresult code, const char * op, const char * file, int line){ if (code != CUresult::CUDA_SUCCESS){ const char * err_name = nullptr ; const char * err_message = nullptr ; cuGetErrorName (code, &err_name); cuGetErrorString (code, &err_message); printf ("%s:%d %s failed. \n code = %s, message = %s\n" , file, line, op, err_name, err_message); return false ; } return true ; } int main () checkDriver (cuInit (0 )); CUcontext ctxA = nullptr ; CUcontext ctxB = nullptr ; CUdevice device = 0 ; checkDriver (cuCtxCreate (&ctxA, CU_CTX_SCHED_AUTO, device)); checkDriver (cuCtxCreate (&ctxB, CU_CTX_SCHED_AUTO, device)); printf ("ctxA = %p\n" , ctxA); printf ("ctxB = %p\n" , ctxB); CUcontext current_context = nullptr ; checkDriver (cuCtxGetCurrent (¤t_context)); printf ("current_context = %p\n" , current_context); checkDriver (cuCtxPushCurrent (ctxA)); checkDriver (cuCtxGetCurrent (¤t_context)); printf ("after pushing, current_context = %p\n" , current_context); CUcontext popped_ctx = nullptr ; checkDriver (cuCtxPopCurrent (&popped_ctx)); checkDriver (cuCtxGetCurrent (¤t_context)); printf ("after poping, popped_ctx = %p\n" , popped_ctx); printf ("after poping, current_context = %p\n" , current_context); checkDriver (cuCtxDestroy (ctxA)); checkDriver (cuCtxDestroy (ctxB)); checkDriver (cuDevicePrimaryCtxRetain (&ctxA, device)); printf ("ctxA = %p\n" , ctxA); checkDriver (cuDevicePrimaryCtxRelease (device)); return 0 ; }
编译
MPS 多进程服务 CUDA MPS(Multi-Process Service)是一种允许多个进程共享单个 GPU 的技术。它允许在同一时间多个进程使用相同的GPU,从而提高GPU的利用率。通过在 GPU 上创建多个 CUDA 上下文来实现的。每个进程都可以创建自己的 CUDA 上下文,并且在这些上下文之间共享 GPU 资源。在 MPS 模式下,多个进程可以并发地使用 GPU,而不会互相干扰
在使用MPS时,需要在每个进程中创建一个CUDA上下文,并且这些上下文需要使用相同的 GPU 设备
开启 MPS 服务
1 sudo nvidia-cuda-mps-control -d
关闭 MPS 服务
1 sudo nvidia-cuda-mps-control quit
在使用 MPS 时,需要避免使用所有 GPU 资源,因为MPS需要一些 GPU 资源来管理多个CUDA上下文。可以使用 nvidia-smi 工具来检查 MPS 所使用的 GPU 资源