摘要
详细讲解 CUDA 流,事件的概念以及声明,以此为基础,深入了解 CUDA 流操作之间的依赖关系,流的同步与异步,以及如何优化事件的创建与管理等等。
CUDA 流
概念
CUDA 流是一系列异步的 CUDA 操作,这些操作按照主机代码所定义的顺序在设备上执行。流会封装这些操作,保持操作的顺序,允许操作在流中排队,并使它们在先前的所有操作之后执行。CUDA 流中的操作可以是主机与设备的内存数据传输,设备内核启动,主机和设备之间的同步等由主机发起但由设备处理的命令
在 CUDA 编程中,一般的执行模式如下
- 将数据从主机传输到设备
- 在设备上执行内核
- 将结果从设备传输回主机
因为不同的 CUDA 流中的操作是异步执行的,这使得它们可以并行运行,不会受到其它流中操作的影响,所以可以将内核执行和数据传输调度到不同的流中,完全隐藏CPU和GPU之间的通信延迟,提高程序的效率
流在 CUDA 的 API 调用粒度上可实现流水线或双缓冲技术。CUDA 的 API函数一般可以分为同步或异步。具有同步行为的函数会阻塞主机端线程,直到它们完成。具有异步行为的函数被调用后,会立即将控制权归还给主机
异步函数和流是在 CUDA 中构建网格级并发的基础。从软件上看,CUDA 操作在不同的流中并发运行,但从硬件上看,不总是如此。根据 PCIe 总线争用或每个SM资源的可用性,完成不同的 CUDA 流可能仍然需要互相等待。下面将详细了解在有多种计算能力的设备上,流是如何运行的
声明
所有的 CUDA 操作都是在流中进行的,流分为
- 隐式声明(空流)
- 显式声明(非空流)
如果没有显式地指定一个流,那么内核启动和数据传输将默认使用空流。在本章之前所有例子都是空流
基于流的异步内核启动和数据传输支持以下类型的粗粒度并发
- 主机计算 - 设备计算
- 主机计算 - 主机与设备间的数据传输
- 设备计算 - 主机与设备间的数据传输
- 并发执行多个设备的计算
我们首先要有一个概念,设备与主机是两个运算节点,以一般的 CUDA 程序举例,下面的 3 个操作会被发布到默认的流中,设备只需要按发布顺序执行,而其他主机上的操作设备一概不知
1 | // ... |
但是主机要等待设备运算,数据向主机传输完成后才能执行后面的操作,也就是之前我们接触到的数据传输都是同步的。不同的是,内核启动是异步的,无论内核是否完成,主机的应用程序都立即恢复执行。
现在介绍一下异步的数据传输,下面是 cudaMemcpy 函数的异步版本
1 | __host__ __device__ cudaError_t cudaMemcpyAsync ( void* dst, const void* src, size_t count, cudaMemcpyKind kind, cudaStream_t stream = 0 ) |
dst:目标地址,指向要复制数据的位置src:源地址,指向要复制的数据的位置count:要复制的字节数。kind:指定复制的方向,可选值为cudaMemcpyHostToDevice、cudaMemcpyDeviceToHost、cudaMemcpyDeviceToDevice和cudaMemcpyDefaultstream:可选参数,指定将异步操作添加到的流
其中stream默认被设置为空流。这个函数与主机是异步的,在调用发布后,控制权将立即返回到主机。
如果我们希望数据传输与非空流关联,可以使用下面的函数显式创建一个非空流
1 | __host__ cudaError_t cudaStreamCreate ( cudaStream_t* pStream ) |
pStream:指向新流标识符的指针
返回到pStream中的流就可以被当作参数给其它异步 CUDA 的 API 函数使用。需要注意的是,当执行异步数据传输时,必须使用固定的主机内存,我们可以使用前面章节提到的两个函数分配固定内存
1 | cudaError_t cudaMallocHost(void **ptr, size_t size); |
在非空流中启动内核,需要注意提供流标识符作为第四个参数
1 | kernel_name<<<grid, block, sharedMemSize, stream>>>(argument list); |
一个非空流声明与创建如下
1 | cudaStream_t stream; |
可以用如下代码释放流中的资源
1 | cudaError_t cudaStreamDestroy(cudaStream_t stream); |
在一个流中,当 cudaStreamDestroy 函数被调用时,如果该流中仍有未完成的工作,cudaStreamDestroy 函数将立即返回,当流中所有工作都已完成时,与流相关的资源将被自动释放
因为所有流都是异步的,有两个专用的函数来检查流中的所有操作是否都已经完成
1 | cudaError_t cudaStreamSynchronize(cudaStream_t stream); |
cudaStreamSynchronize函数用于强制阻塞主机,直到给定流中的所有操作都完成
1 | cudaError_t cudaStreamQuery(cudaStream_t stream); |
cudaStreamQuery函数用于检查流中的所有操作是否都已经完成,但不会阻塞主机。当所有操作都完成时函数会返回cudaSuccess。否则返回cudaErrorNotReady
下面这段代码是使用流的一个例子,在多个流中执行 CUDA 核函数和数据传输操作
1 | for (int i = 0; i < nStreams; i++) { |
流在 CUDA 中执行的时间轴如下图所示,H2D 是主机到设备的内存传输,D2H 是设备到主机的内存传输。数据传输和内核执行分布在 3 个并发流中,但是在执行时,数据传输并没有并发执行,这是因为 PCIe 总线是共享的,当第一个流占据了总线,后面的流就要等待总线空闲,但是如果 H2D 和 D2H 同时发生,就不会产生等待,而是同时进行

流调度
前面我们说到,所有流都可以同时运行,但在硬件中没有流的概念,而是包含一个或多个执行内存拷贝操作的引擎和执行核函数的引擎。这些引擎彼此独立地对操作进行排队,这将导致如下图所示的任务调度情形
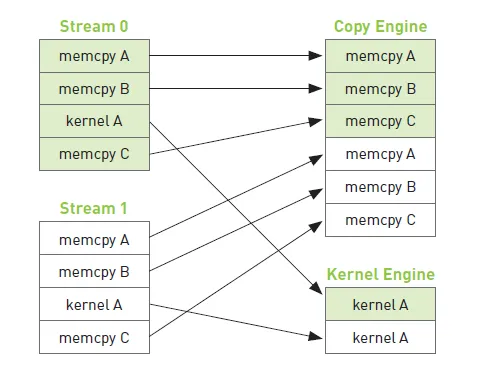
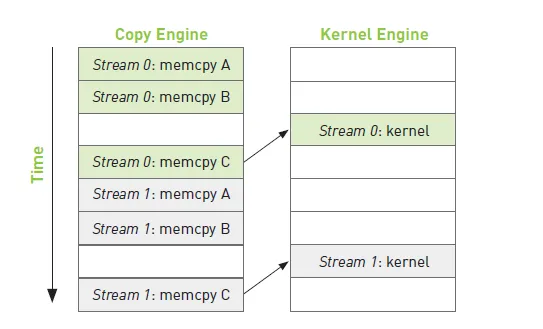
在不同流的操作中,存在相互的依赖,比如 memcpy A B C 为从主机拷贝数据到设备内存,kernel 需要等待 memcpy A B C 操作完成后再执行,Stream 1 需要等待 Stream 0 完成操作后再执行,如下图所示
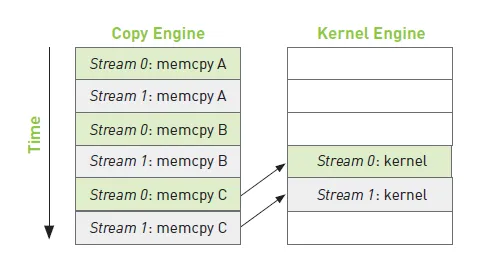
为了避免这个问题,我们可以交错地执行不同流的拷贝内存操作和核函数运算操作,如下图所示
为了解决多个 Kernel 函数同时在 GPU 中运行的问题,节省代码编写成本,从 Kepler 架构开始,Nvidia 推出了 Hyper-Q 硬件技术,主机与设备之间最多可以建立 32 个工作队列,每个流分配一个工作队列,如果创建的流超过32个,则多个流共用一个工作队列
同时 Hyper-Q 技术还可以使不同流中的计算和使用带宽能够重叠,最大化 GPU 的资源利用率。例如 Stream1 中的计算要占用 60% 的核心和 60% 的显存带宽,而 Stream2 中的计算要占用 70% 的核心和 50% 的显存带宽,二者同时运行时会按一定的比率争用 GPU 资源
流优先级
对于计算能力在 3.5 以上的设备可以分配流的优先级,下面函数创建一个有指定优先级的流
1 | __host__ cudaError_t cudaStreamCreateWithPriority ( cudaStream_t* pStream, unsigned int flags, int priority ) |
pStream:一个指向cudaStream_t类型的指针,用于存储创建的流的句柄flags:流的行为标志,可选参数,默认为0。当前支持的标志只有cudaStreamNonBlocking,指定在创建的流中运行的工作可以与 Stream0(空流)中的工作同时运行,并且创建的流不应该与 Stream0 执行隐式同步priority:流的优先级,较低的数字代表较高的优先级。0 表示默认优先级。 可以使用cudaDeviceGetStreamPriorityRange查询有意义的数值优先级范围。 如果指定的优先级超出了cudaDeviceGetStreamPriorityRange返回的数值范围,它将自动被限制在范围内的最低或最高数字
不同的设备有不同的优先级等级,下面函数可以查询当前设备的优先级分布情况
1 | __host__ cudaError_t cudaDeviceGetStreamPriorityRange ( int* leastPriority, int* greatestPriority ) |
leastPriority:指向整数的指针,返回设备支持的最低优先级greatestPriority:指向整数的指针,返回设备支持的最高优先级
笔主的显卡优先级等级范围为 [0, -5]
CUDA 事件
概念
CUDA 事件是 CUDA 流中的一个标记点,检查正在执行的流操作是否已经到达了该点。使用事件可以用来执行以下两个基本任务
- 同步流的执行
- 监控设备的进展
CUDA API 提供了在流中任意点插入事件以及查询事件完成的函数。只有当一个 CUDA 流中,事件标注点之前的所有操作都执行完成后,该事件才会完成,在默认流中的指定事件,适用于 CUDA 流中先前的所有操作
声明
一个 CUDA 事件声明如下
1 | cudaEvent_t event; |
创建事件
1 | __host__ cudaError_t cudaEventCreate ( cudaEvent_t* event ) |
销毁事件
1 | __host__ __device__ cudaError_t cudaEventDestroy ( cudaEvent_t event ) |
如果回收指令执行的时候事件还没有完成,那么回收指令立即完成,当事件完成后,资源被回收
事件也可以看作是流的一次操作,通过下面函数排队添加到 CUDA 流
1 | __host__ __device__ cudaError_t cudaEventRecord ( cudaEvent_t event, cudaStream_t stream = 0 ) |
在流中的事件用于等待前面的操作完成,或测试流中操作的完成情况,可以使用下面的函数阻塞主机线程直到事件被完成,类似于cudaStreamSynchronize函数
1 | __host__ cudaError_t cudaEventSynchronize ( cudaEvent_t event ) |
cudaEventQuery函数用于检查事件之前的所有操作是否都已经完成,但不会阻塞主机。当所有操作都完成时函数会返回cudaSuccess。否则返回cudaErrorNotReady。类似于cudaStreamQuery
1 | __host__ cudaError_t cudaEventQuery ( cudaEvent_t event ) |
记录事件和计算运行时间
下面函数记录两个事件 start 和 stop 之间的时间间隔,毫秒单位。此外,这两个事件可以在不同流中
1 | __host__ cudaError_t cudaEventElapsedTime ( float* ms, cudaEvent_t start, cudaEvent_t end ) |
下面是一段记录事件时间间隔的示例代码,两个事件被插入到空流中,作为标记,然后记录他们之间的时间间隔。但是这里时间间隔可能会比实际大一些,因为这里用到 cudaEventRecord 函数是异步的,计算会有延时
1 | // create two events |
流同步
在非空流中,所有操作对于主机来说都是并行的,如果我们想在某一刻等待,执行当前时刻所有操作同步,就会导致等待时资源的闲置,浪费性能
从主机的角度,CUDA 操作可以分为两类
- 内核启动
- 内存操作
其中内核启动总是异步的,内存操作可以是同步或异步
前面我们说到有两种类型的流,按同步异步分,又可分为
- 同步流(空流)
- 异步流(非空流)
显式声明的都是异步流,异步流通常不会阻塞主机。而在隐式声明的同步流中,部分操作会造成阻塞,让主机等待
异步流并不都是非阻塞的,可进一步分为如下两种类型
- 阻塞流
- 非阻塞流
如果一个异步流被声明为非阻塞的,就不会被空流阻塞,如果声明为阻塞流,则会被空流阻塞
阻塞流与非阻塞流
cudaStreamCreate创建的是阻塞流,意味着流中的操作可以被阻塞,直到空流中某些操作完成。任何发布到阻塞流中的操作,都要等待空流中先前的操作执行结束才开始执行
举例代码如下
1 | Kernel1<<<1, 1, 0, Stream1>>>(); |
Kernel1在执行结束后才执行 Kernel2,Kernel2 执行结束后才执行 Kernel3
下面的函数用于创建一个非阻塞流
1 | __host__ __device__ cudaError_t cudaStreamCreateWithFlags ( cudaStream_t* pStream, unsigned int flags ) |
pStream:一个指向cudaStream_t类型的指针,用于存储创建的流的句柄flags:流的行为标志,可选参数,默认为0。当前支持的标志只有cudaStreamNonBlocking,指定在创建的流中运行的工作可以与 Stream0(空流)中的工作同时运行,并且创建的流不应该与 Stream0 执行隐式同步
隐式同步
这里的同步也可以说是阻塞,例如在调用 cudaMemcpy 函数时,会隐式同步设备和主机,也可以说其它操作在数据传输完成前都会被阻塞。运行带有隐式同步行为的操作时会导致不必要的阻塞,造成性能下降。此外,如下与内存有关的操作都会有隐式同步,需要格外注意
- 锁页主机内存分布
- 设备内存分配
- 设备内存初始化
- 同一设备上两地址之间的内存复制
- 一级缓存/共享内存配置修改
显式同步
常见的显式同步有
- 同步设备:
cudaDeviceSynchronize - 同步流:
cudaStreamSynchronize,cudaStreamQuery - 同步流中的事件:
cudaEventSynchronize,cudaEventQuery - 使用事件跨流同步:
cudaEventRecord,cudaStreamWaitEvent
其中,除了最后一个函数,其他我们都有所介绍
1 | __host__ __device__ cudaError_t cudaStreamWaitEvent ( cudaStream_t stream, cudaEvent_t event, unsigned int flags = 0 ) |
stream:要等待事件的 CUDA 流event:等待的 CUDA 事件flags:控制等待事件时的行为。可选参数,默认为 0。可以使用cudaEventBlockingSync(阻塞同步)或cudaEventDisableTiming(禁用事件记录)等标志
这个函数的作用是指定的流等待指定的事件,事件完成后流才能继续,其中的事件可以在任意流中,当在不同的流的时候,就实现了事件跨流同步
如下图所示,Stream2 在调用 cudaStreamWaitEvent 函数后执行跨流同步,确保 Stream1 创建的事件是满足依赖关系的

可配置事件
1 | __host__ __device__ cudaError_t cudaEventCreateWithFlags ( cudaEvent_t* event, unsigned int flags ) |
event:指向cudaEvent_t类型的指针,用来存储创建的CUDA事件对象flags:用来指定事件对象的创建标志
其中 flag 可选参数如下
cudaEventDefault:默认事件创建标志cudaEventBlockingSync:指定事件应该使用阻塞同步。 使用cudaEventSynchronize()等待使用此标志创建的事件的主机线程将阻塞,直到事件实际完成cudaEventDisableTiming:指定创建的事件不需要记录计时数据。 当与cudaStreamWaitEvent()和cudaEventQuery()一起使用时,使用指定此标志创建的事件和未指定cudaEventBlockingSync标志将提供最佳性能cudaEventInterprocess:指定创建的事件可以用作进程间事件,cudaEventInterprocess必须与cudaEventDisableTiming一起指定