摘要
原文链接:https://arxiv.org/pdf/2306.10209.pdf
开源代码:https://github.com/microsoft/deepspeed
背景
面对 LLM,3D并行工程实现复杂
介绍
通过以下 3 种方法减少通信
- 基于块量化的 all-gather
- 通过数据重映射用通信减少内存开销
- 基于 all-to-all 的量化梯度平均方法,替代 reduce-scatter
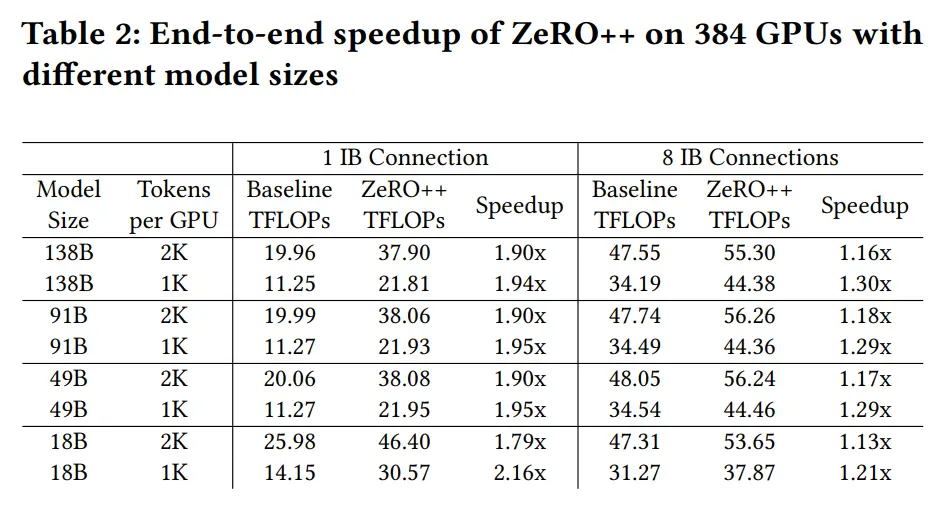
ZeRO++将 ZeRO 的通信量减少了 4 倍,并在低精度下保持准确性,使得在 384 张 GPU下,吞吐量可以提高 2.16 倍
Limitations of ZeRO
在低带宽集群中,单卡的吞吐量只有高带宽集群的一半,即使在高带宽集群中,使用数千个 GPU 进行训练,单卡的 batch size 也受到 global batch size 的限制(global batch size 不能无限增加,否则会降低模型收敛效率)
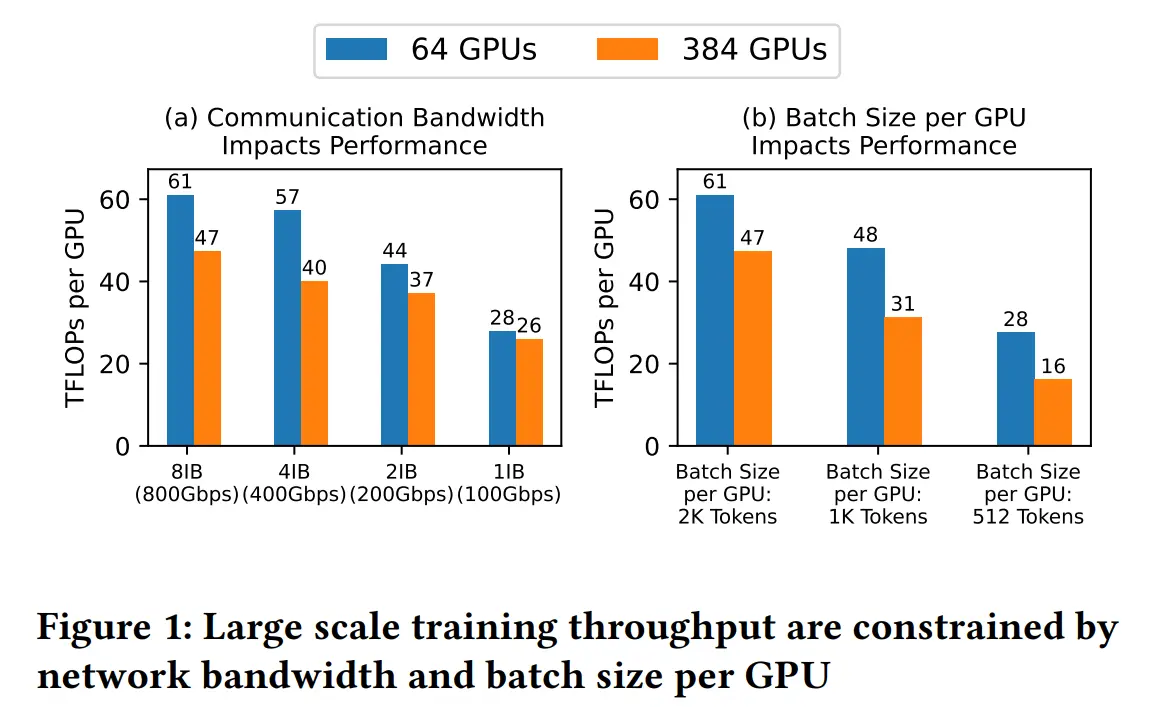
所以在千卡训练时,单卡的 batch size 必须非常小,这会降低计算与通信的比率
ZeRO 由于对模型状态进行分区,无法直接对模型状态复制,所以与之前的节省通信工作不兼容
ZeRO++
假设模型参数量为 M
FWD:参数 all gather
BWD:参数 all gather,梯度 reduce scatter
通信量总计 3M
Quantized Weight Communication (qwZ)
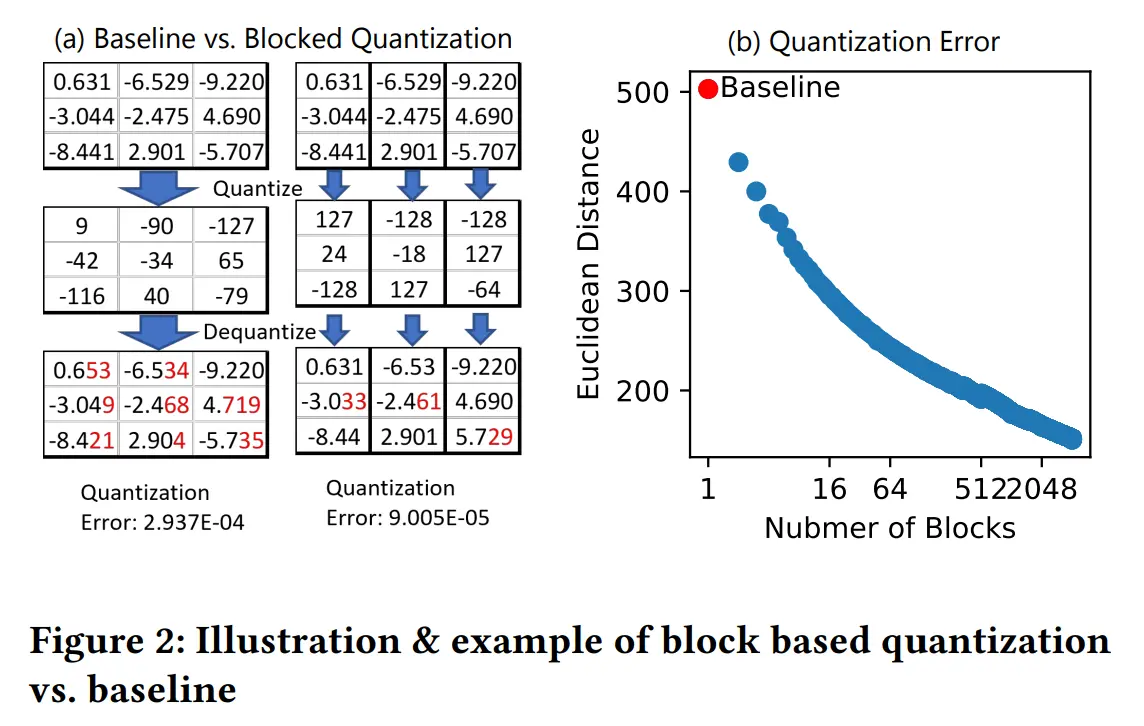
通信前,将参数从 fp16 量化为 int8,为了保证训练准确率,使用 block-based 量化的思想,并使用 CUDA kernel 保证高性能
Hierarchical Weight Partition (hpZ)
在单个节点中保存整个模型参数的副本,通过节点内的 all gather 代替节点间通信,牺牲显存,节省通信
Quantized Gradient Communication (qgZ)
直接在 reduce scatter 之前量化会影响精度,可以在通信过程中使用 block-based INT4 量化压缩梯度,并在发送后恢复保证训练精度
两步通信,先节点内通信,再节点间通信
节点间通信使用流水线策略,融合 CUDA Kernel
Communication Volume Reduction
qwZ: 1M → 0.5
hpZ: 1M → 0M
qgZ: 1M → 0.25M
all: 3M → 0.75M
先前工作
3D 并行
3D 并行训练流程
- all gather 参数
- FWD
- partition
- all gather
- BWD
- partition
- reduce scatter
- 优化器更新
ZeRO 优化器
ZeRO-3 最高效利用内存,但需要多次通信解决分区问题
Communication Reduction Techniques
量化问题:fp32/16 对比 int8 有数据范围和粒度的差异
改进方法:
过滤异常值,缩小数值范围差距,但准确性被滤波算法影响,且有时间开销
分块量化优化器状态,但需要修改模型结构
梯度压缩:1-bit adam/lamb 可以实现高效的通信,但必须保证每个 GPU 上都有梯度副本,由于 ZeRO-3 的分区策略,不能应用
ZeRO Communication Reduction
MiCS (基于 DeepSpeed-v0.4.9 和 PyTorch-v1.11):对节点分组,每个组保存模型状态的完整副本。在每个组内,模型状态被分区,使最频繁的参数 all gather操作在每个组上进行,且并行多个节点间的集体通信,在组内的梯度达到边界,则进行组间通信,此外,还采用了细粒度同步、合并通信 API 和内存碎片整理等优化
hpZ 与 MiCS 类似,但只对权重分组,在每个 gpu 上保留对模型状态的分区,相比 MiCS 节省了内存
设计
qwZ
为了解决精度下降严重的问题,使用块量化的思想,将每个权重张量被划分为更小的块,然后使用独立的量化缩放系数进行对称量化为 INT8,减少了 3 倍量化误差
hpZ
采用两级分区策略
- 全局主分区:所有模型状态在所有设备上全局分区(如ZeRO-3)
- 次级分区:在次全局级别(例如,计算节点)创建 FP16 参数的次级副本,并在多个次级分区中复制
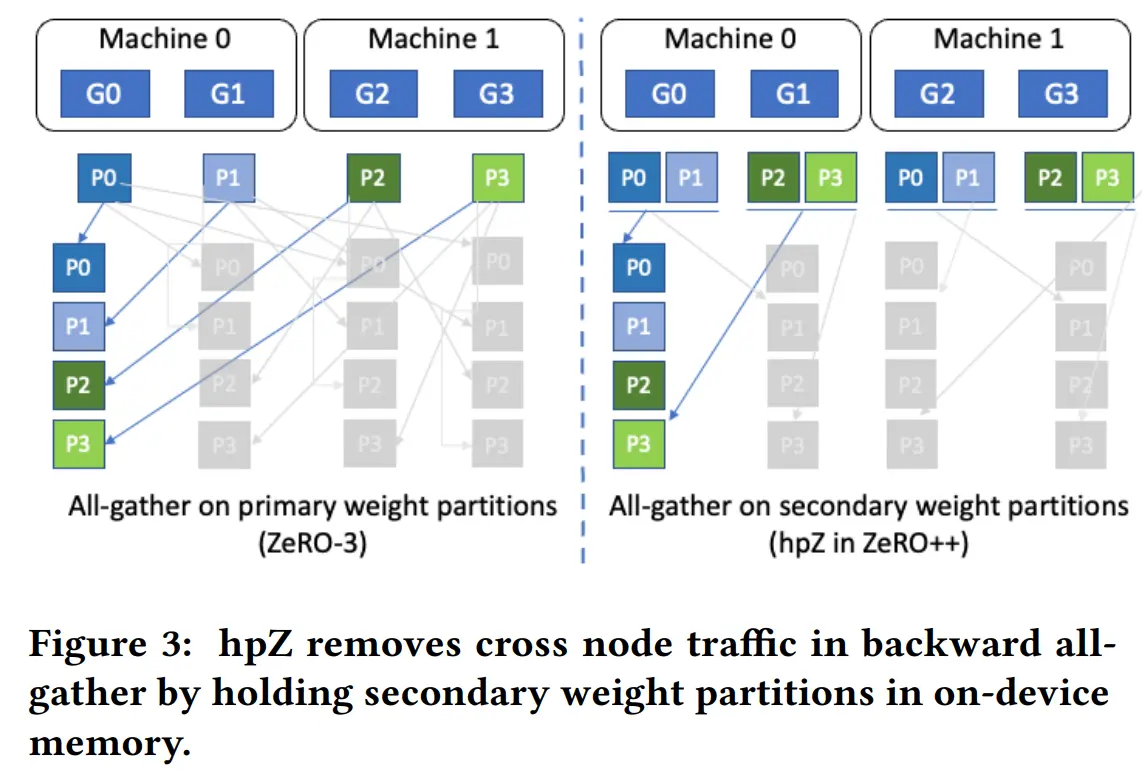
在 FWD 阶段,对权重在主分区上 all gather。权重在 FWD 后,根据次级分区进行分区。由于 FWD/BWD 之间模型参数的存在时序一致性,在 BWD 中再次需要权重时,基于次级分组进行 all gather
当次级分区设置为计算节点时,避免了 all gather 过程中的跨节点通信
在迭代结束时,在优化器步骤中,所有模型状态以及 FP16 参数的主副本都根据主分区更新
支持任何次级分区大小,并控制次级分区中的GPU数量

qgZ
基于 all-to-all 的量化梯度通信策略,只在通信之前量化梯度,但在任何 reduce 操作之前将它们反量化到原有精度 ,功能上等同于压缩的 reduce-scatter 操作
解决了两个问题:
- 简单地在 INT4/INT8 中实施 reduce-scatter 会导致显著精度损失
- 在传统 tree 或 ring-based reduce-scatter 中使用量化需要一长串量化和反量化步骤,这直接导致误差积累和显著的延迟
qgZ 不使用tree或ring-based reduce-scatter算法,而是基于一种新的分层 all-to-all 方法
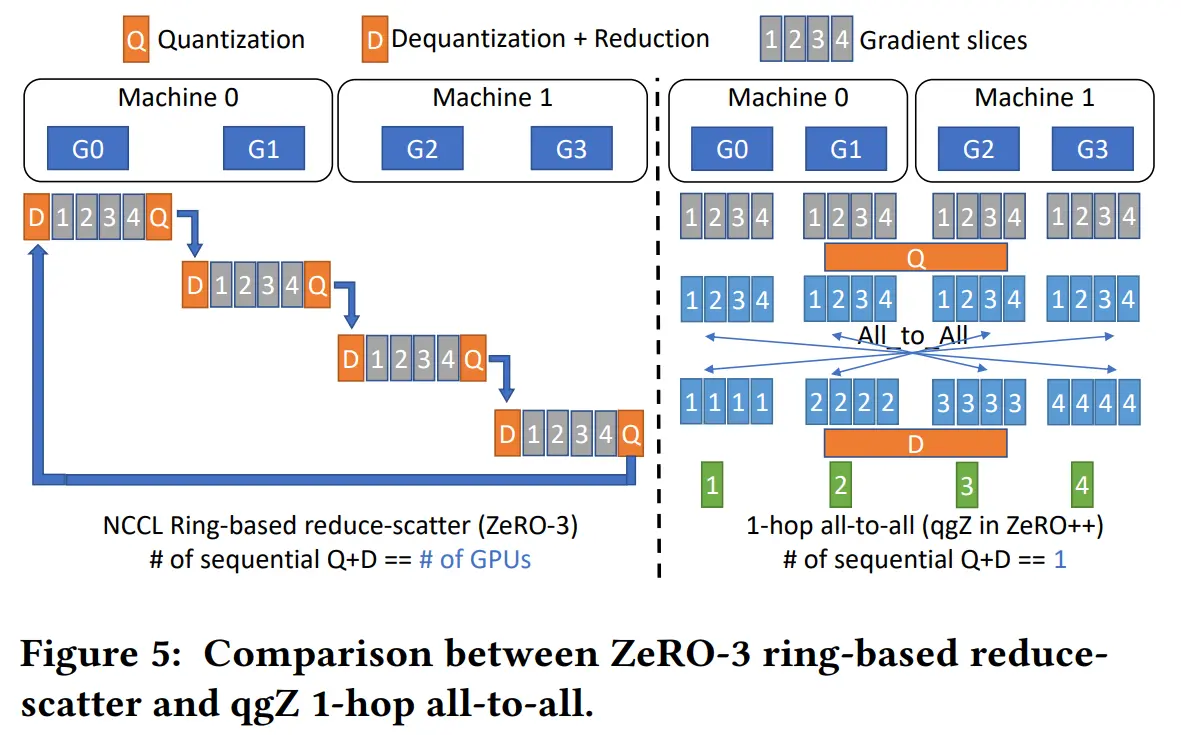
qgZ 中有三个主要步骤:
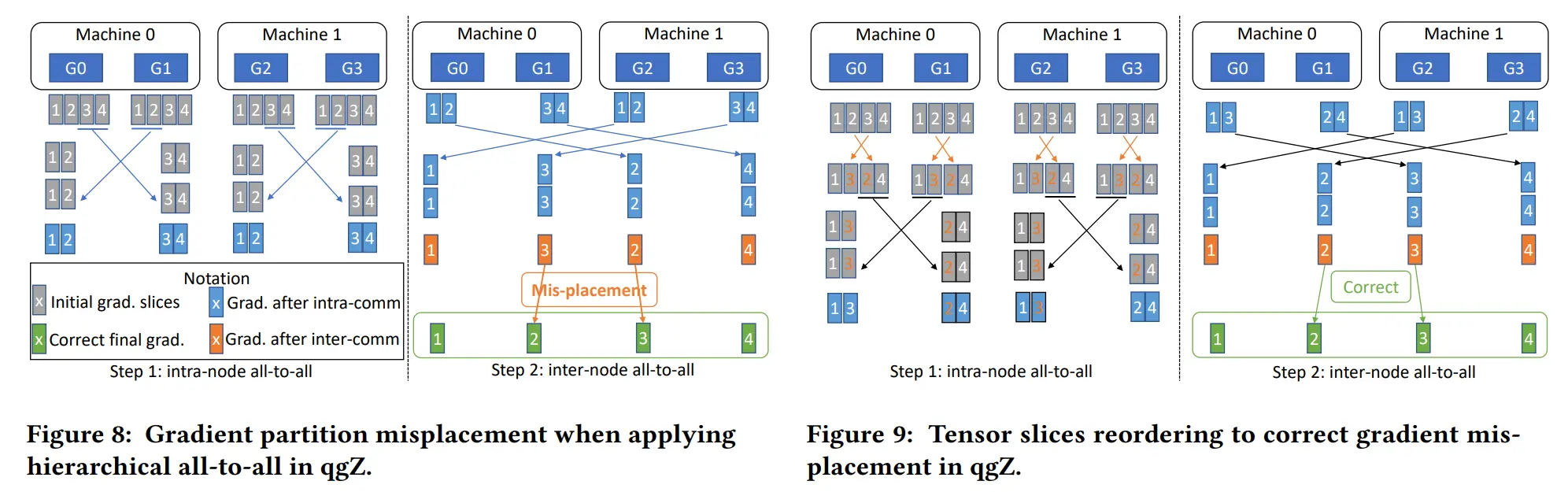
- 梯度切片重新排序,在任何通信发生之前,对梯度进行切片并对张量切片重新排序,以保证通信结束时每个 GPU 上的最终梯度位置是正确的
- 节点内通信和 reduce,量化重新排序的梯度切片,在每个节点内进行 all-to-all 通信,从 all-to-all 中对接收到的梯度切片进行反量化,并进行局部 reduce
- 节点间通信和 reduce,再次量化局部reduce后的梯度,进行节点间的all-to-all通信,再次对接收到的梯度进行反量化,并计算最终的高精度梯度 reduce
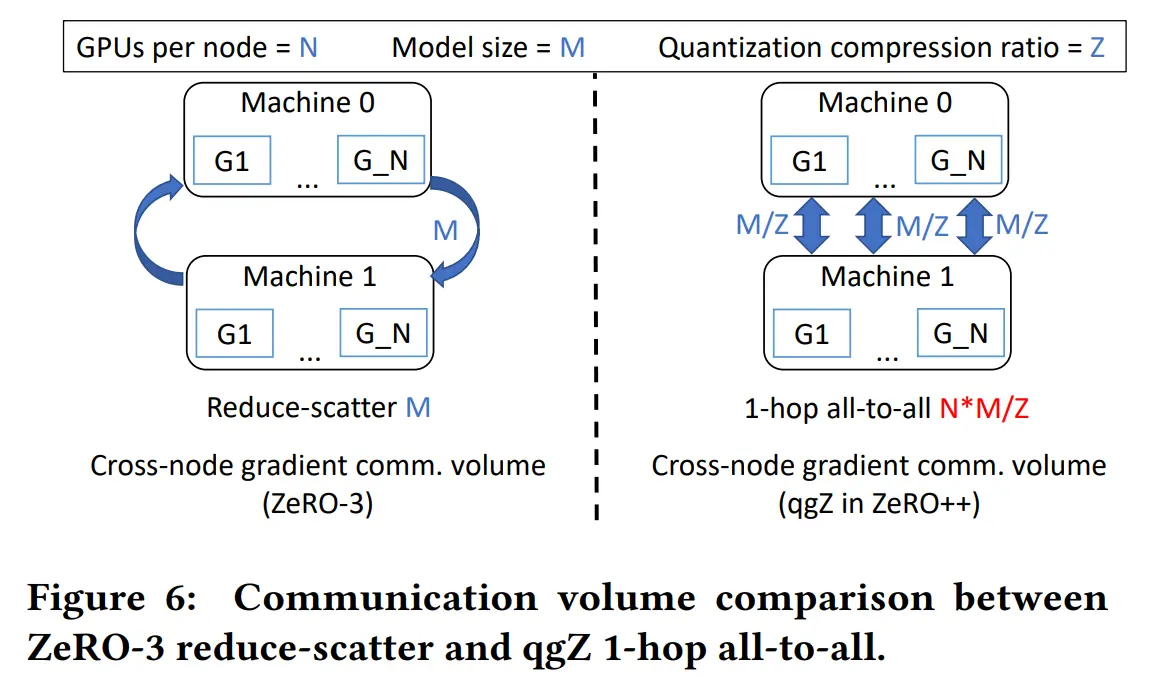
给定每个节点 N 个 GPU、M 的模型大小和 Z 的量化比率,NCCL all-to-all 将生成 M*N/Z 跨节点流量
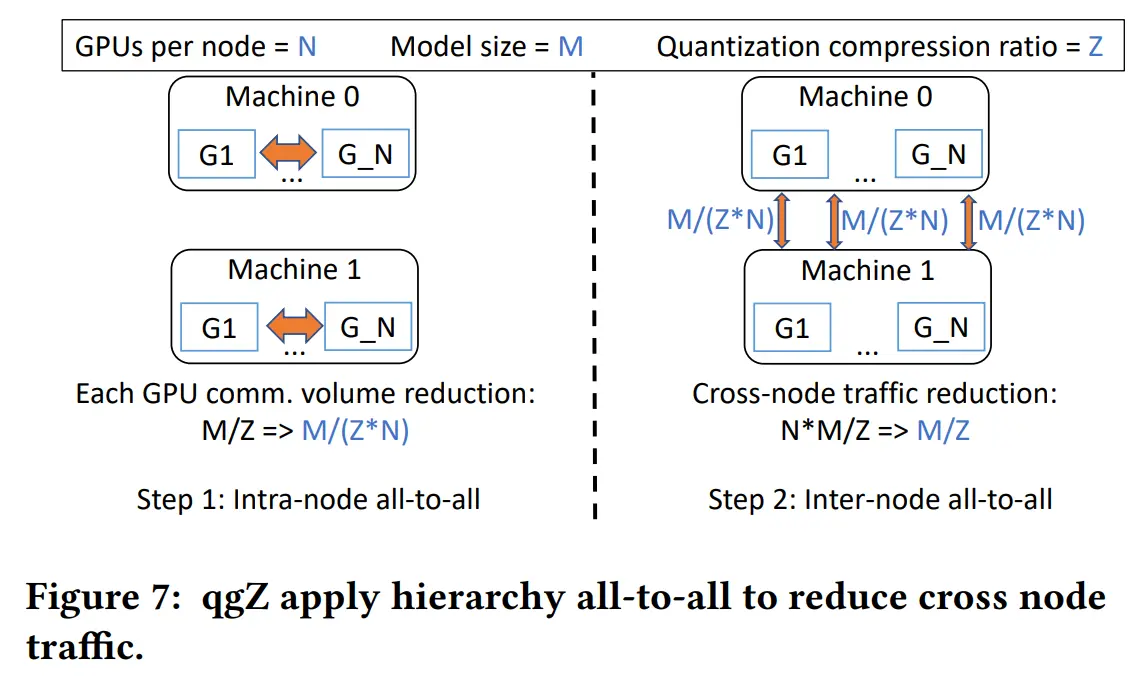
相比之下,通过 qgZ,将每个 GPU 的跨节点流量从 M/Z 减少到 M/(ZN)。 因此,总通信量从 MN/Z 减少到 MN/(ZN) = M/Z
此外,通过重叠节点内和节点间通信以及融合 CUDA 内核来进一步优化 qgZ 的端到端延迟
- 张量切片重新排序 (Tensor Slice Reordering)
- 节点内量化 (Intra-node quantization)
- 节点内反量化 (Intra-node Dequantization)
- 节点内梯度整合 (Intra-node Reduction)
- 节点间量化 (inter-node quantization)
优化实现
Overlap Compute and Communication
- 根据模型层的执行顺序
- 保证量化异步执行
获取每一层的参数,在不同的 CUDA 流上同时启动当前层的通信和下一层的量化。当下一层需要量化数据时,ZeRO++同步量化流以确保量化数据准备就绪
这可以在当前层的通信时间跨度下隐藏了下一层的量化成本,隐藏了量化开销
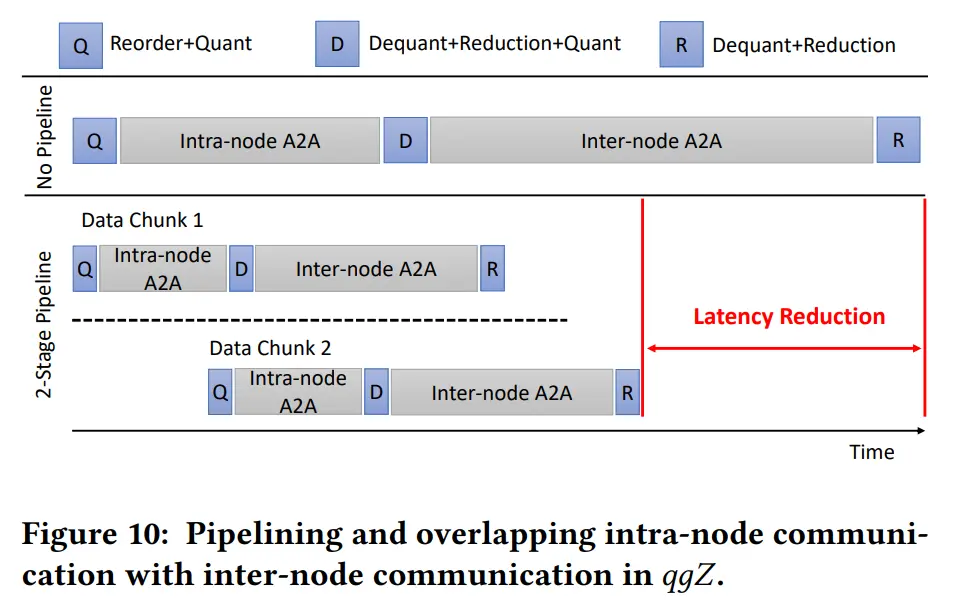
基于 all to all 的梯度通信分为两个阶段:节点内通信和节点间通信
为了利用节点间通信执行时,节点内通信的空闲,实现了输入梯度张量的分块和 pipeline 传输
pipeline 阶段越多,重新排序所需的细粒度张量切片就越多
提出了一种广义张量切片重新排序算法,涵盖了 w/ 和 w/o pipeline 数据传输的情况
这里的 stages 是指拥有的 pipeline stage 的数量,nodeSize 是每个节点的 GPU 数量,nodes 是节点的数量

CUDA Kernels
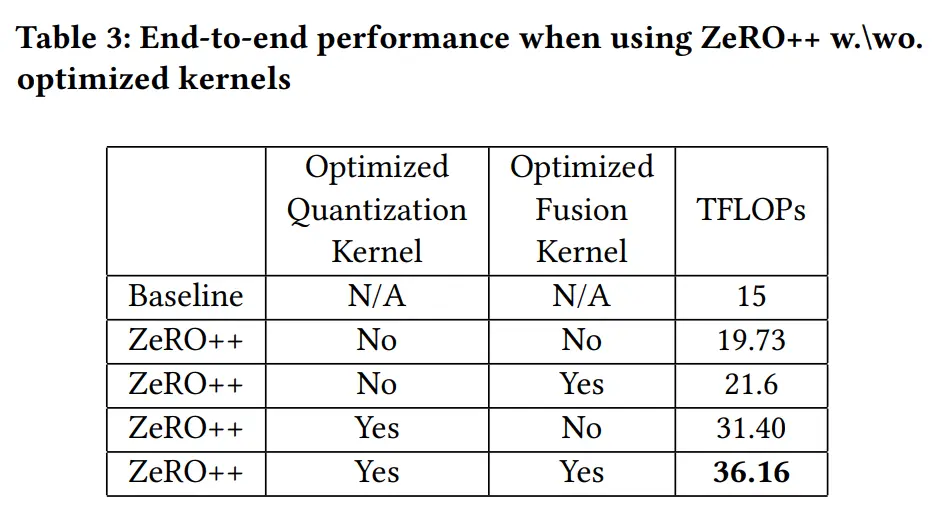
为了最大化带宽利用和最小化内核开销,论文中实现并优化了自定义CUDA核心,用于实现量化操作
开发了一个可组合运算符的核心量化和反量化库,利用高效的向量化内存访问来满足给定GPU架构支持的最大粒度。此外,利用指令级并行性重叠多个内存事务
使用多种技术减少量化内核的总内存流量。例如,调整每个量化块的大小,将张量重塑和量化融合到同一内核中,避免从全局内存中重复加载数据
此外,将连续的反量化、减少和量化操作融合到单一内核实现中
减少了 9 倍的内存流量
实验
配置
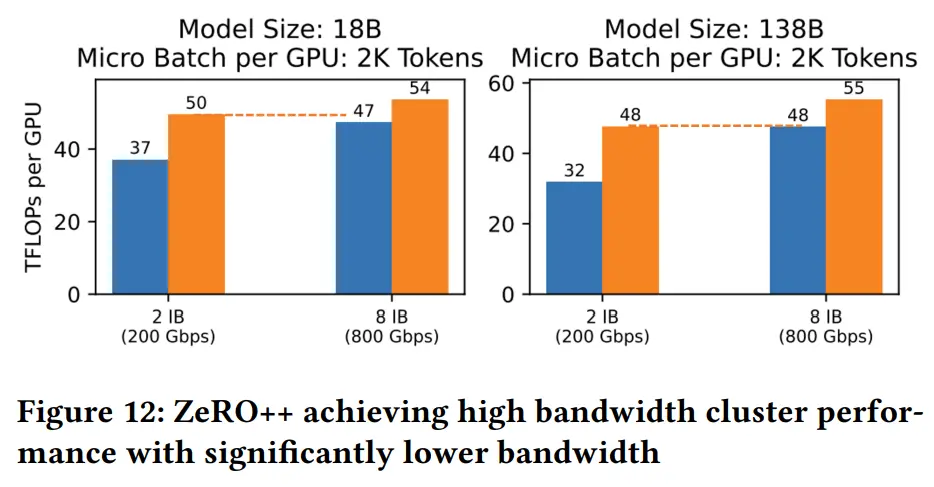
- 硬件配置:使用包含16个V100 SXM3 32 GB GPU的24个NVIDIA DGX-2节点。这些节点通过具有NVIDIA SHARP支持的InfiniBand(IB)连接,实现超过800 Gbps的节点间带宽
- 测试环境:为了评估ZeRO++在不同网络环境下的性能,展示了通过启用1到8个IB连接(即100 Gbps到800 Gbps)的ZeRO++运行性能
- 基准设置:使用ZeRO-3作为基准,因其便于大规模训练巨型模型。同时,为了评估优化内核的性能,还使用了PyTorch量化和非融合内核实现的ZeRO++作为消融研究的基线
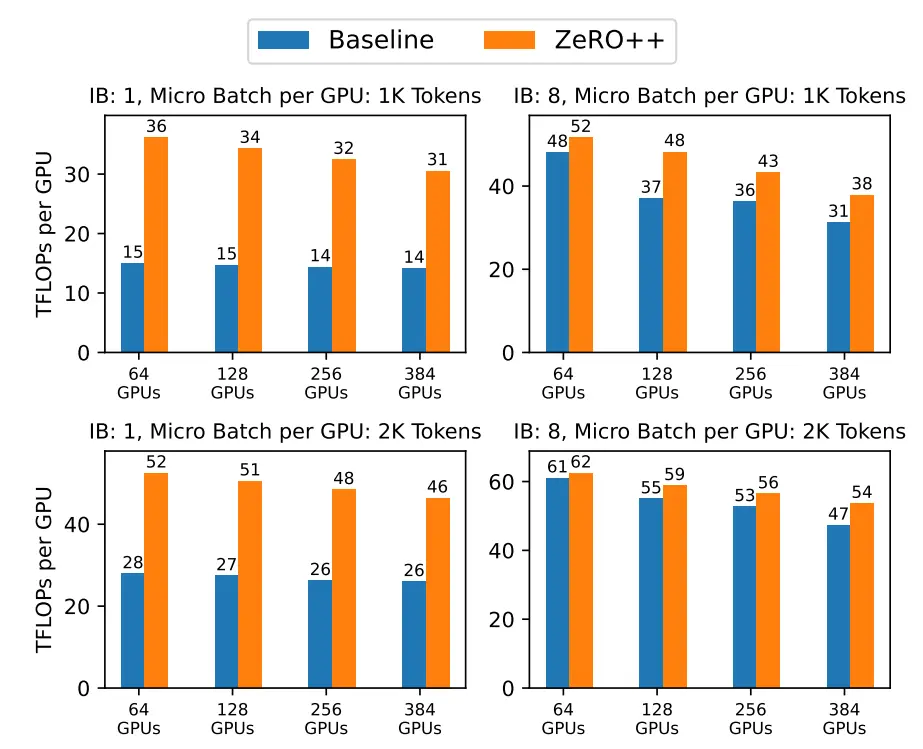
- 模型配置:基于Megatron-Turing-NLG训练530B模型在2000个GPU上使用每GPU 2000 token的设置,对ZeRO++使用相同的2000 token设置进行评估。还评估了每 GPU 1000 token的设置,以测试ZeRO++在更极端规模的场景下的性能。调整层数和隐藏层大小以构建不同大小的模型
结果
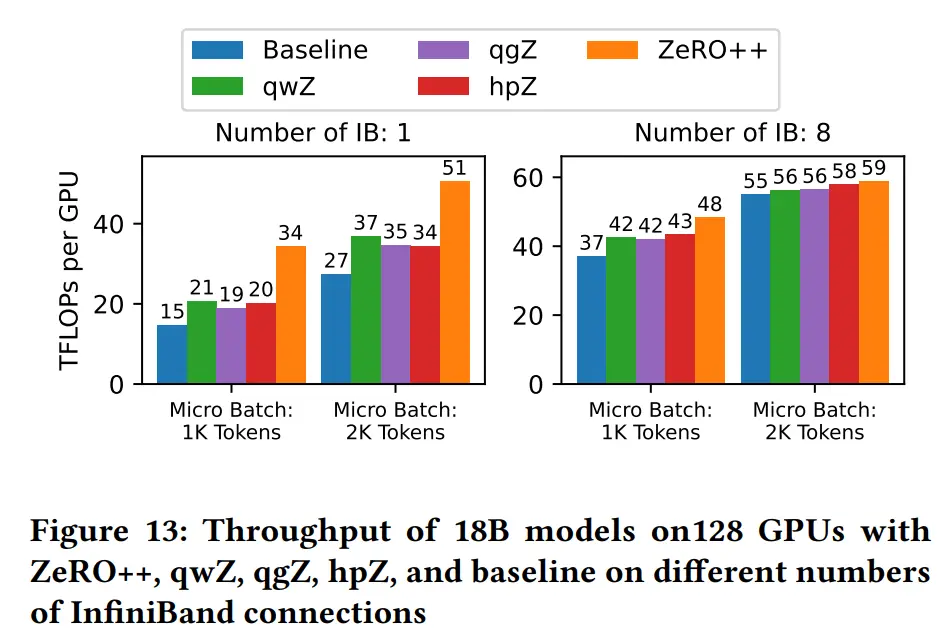
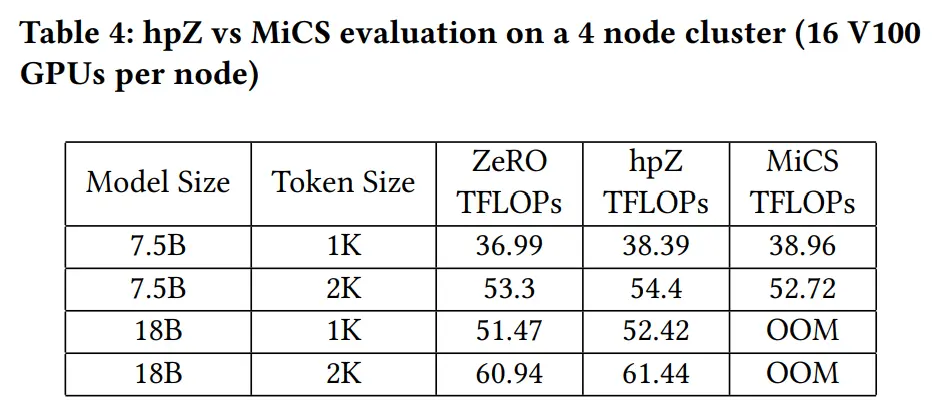
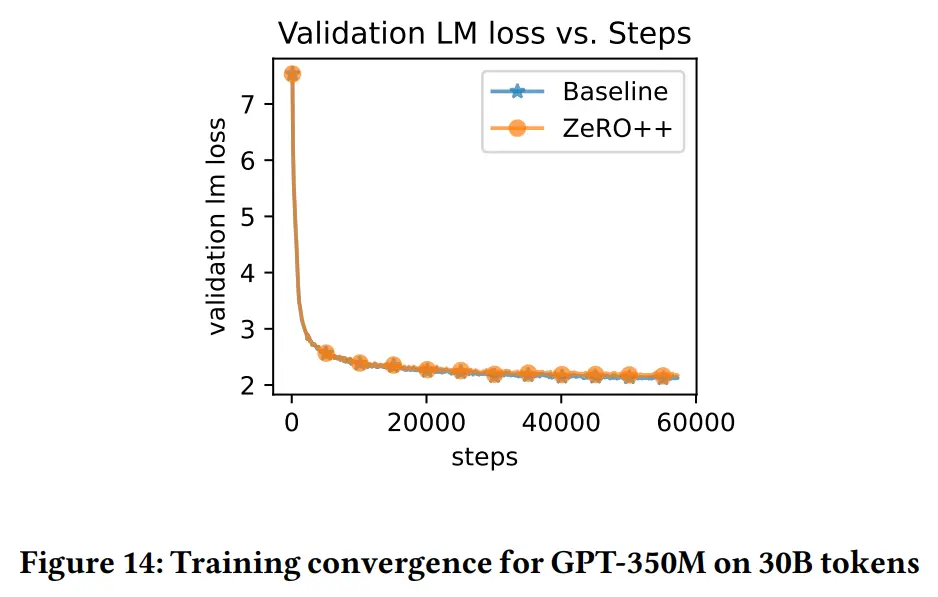
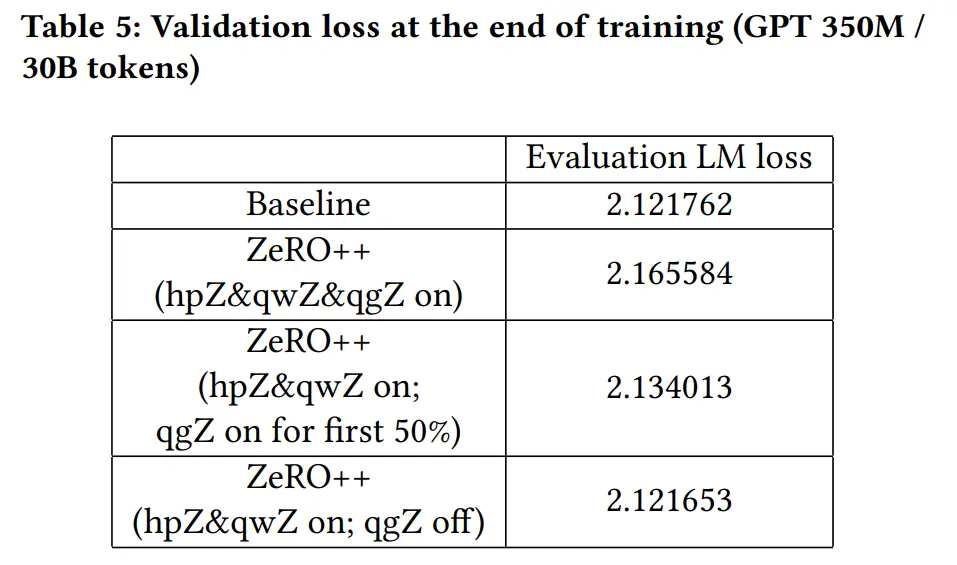
结论
合并上述三项优化,使用 384 V100 GPU 进行大规模模型训练时系统吞吐量提高 2.16 倍