摘要
ZeRO-Infinity 是基于 ZeRO 的扩展,Infinity 离线引擎可以同时利用 GPU、CPU 和 NVMe 内存,还提出了其他的优化技术。
原文链接:https://arxiv.org/pdf/2104.07857.pdf
开源代码:https://github.com/microsoft/deepspeed
背景
GPU 内存墙:模型规模成长了 1000 倍,但 GPU 内存只增长了 5 倍
介绍
ZeRO-Infinity 是基于 ZeRO 的扩展,Infinity 离线引擎可以同时利用 GPU、CPU 和 NVMe 内存,还提出了以下三个技术
- Memory-Centric Tiling:减少大规模操作的GPU内存需求,而无需 MP
- Bandwidth-Centric Partitioning:技术利用所有并行设备的聚合内存带宽
- Ease-Inspired Implementation:避免模型代码重构
先前工作
ZeRO:https://arxiv.org/abs/1910.02054
ZeRO-Offload:https://arxiv.org/pdf/2101.06840.pdf
显存需求
这一节没有根据论文的内容写,论文讲的太简略了,看的糊里糊涂
内存可以从两个方面优化
- 模型状态:梯度,参数,优化器状态
- 剩余状态:中间激活值、临时buffer、显存碎片等。下面我们只讨论中间激活值的显存占用
模型状态内存
模型参数量
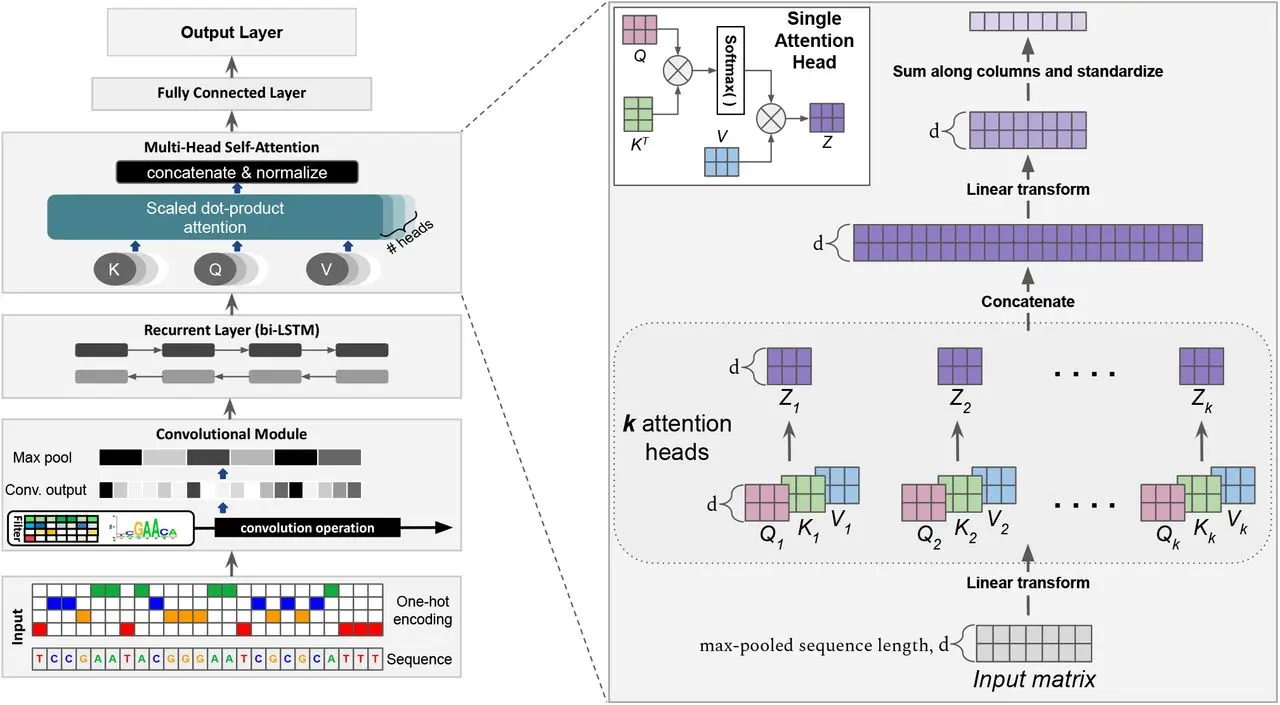
为了方便分析,定义 transformer 模型的层数为 l,隐藏层维度为 h,注意力头数为 a。
词表大小为 v,训练数据的批次大小为 b,序列长度为 s
transformer模型由 l 个相同的层组成,每个层分为 self-attention 块和 MLP 块
self-attention:参数有 q, k, v 的权重矩阵和 wq, wk, wv 的偏置 bq, bk, bv,输出权重矩阵 wo 和偏置 bo,4 个权重矩阵的形状为 [h, h],4个偏置的形状为 [h]。所以 self-attention 块的参数量为 4h^2 + 4h
MLP:由 2 个线性层组成,一般第一个线性层是先将维度从 h 映射到 4h ,第二个线性层再将维度从 4h 映射到 h。第一个线性层的权重矩阵 的形状为 [h,4h] ,偏置的形状为 [4h] 。第二个线性层权重矩阵的形状为 [4h,h] ,偏置形状为 [h] 。所以 MLP 块的参数量为 8h^2+5h
layer normalization:self-attention 块和 MLP 块各有一个 layer normalization,包含可训练的缩放参数和平移参数,形状都是 [h] 。2个layer normalization的参数量为 4h
所以每个 transformer 层的参数量为 12h^2+13h,此外还有
- embdding 层:维度通常等于隐藏层维度 h,参数量为 vh。最后的输出层的权重矩阵通常与 embdding 层是参数共享的
- 位置编码:如果采用可训练式的位置编码,会有一些可训练模型参数,数量比较少。如果采用相对位置编码,例如 RoPE 和 ALiBi,则不包含可训练的模型参数。这里忽略这部分参数
综上,l 层 transformer 模型的可训练模型参数量为 l(12h^2+13h)+vh。当隐藏维度 h 较大时,可以忽略一次项,近似为 12lh^2
目前主流的大模型训练方法是使用 Adam 优化器进行混合精度训练,参数和梯度存储为 FP16,优化器状态包括 FP32 的动量、方差、参数和梯度,因此每个参数需要 20b(22b + 44b) 的显存,总显存占用就是 240 lh^2 字节
剩余状态内存
中间激活值
可以理解为前向传递过程中计算得到的,并在后向传递过程中需要用到的所有 tensor
- layer normalization 层:计算梯度时需要用到层的输入 bsh 字节,输入的均值和方差 bs 字节,由于 h 一般是千位,所以 layer normalization 显存近似为 bsh 字节
- dropout 层:在训练中存储为 mask 矩阵,每个元素只占 1 字节
每个 transformer 层包含了一个 self-attention 块和 MLP 块,并分别对应一个 layer normalization 连接
self-attention
计算公式为
Q, K, V:需要保存共同输入 x,这就是中间激活,x shape 为 [b, s, h],元素个数为 bsh,占用显存为 2bsh 字节
这里的 shape 中没有 a 是因为在计算时,每个 head 对应的 hidden size 被除以了 head,一乘一除,化简了
QK^T:需要保存 Q, K,shape 都是 [b, s, h],占用显存大小为 4bsh
softmax():需要保存函数输入 QK^T,Q shape [b, a, s, h],K^T shape [b, a, h, s],QK^T shape [b, a, s, s],占用显存为 2bs^2adropout:计算完 softmax 后得到 score,需要计算 dropout,保存 mask 矩阵,shape 与 QK^T 相同,占用显存为 bs^2a
计算 v 上的 attention ,score * v,需要保存 score:2bs^2a ,v:2bsh,总合 2bs^2a+2bsh
计算输出映射和一个 dropout,输出映射需要保存其输入,2bsh 字节,结合 dropout 3bsh
综上所述,self-attention 块中间激活占用显存为 11bsh + 5bs^2a 字节
MLP
计算公式为
- linear_1:2bsh
- 激活函数:8bsh
- linear_2:8bsh
- dropout:bsh
综上所述,MLP 块中间激活占用显存为 19bsh 字节
另外,self-attention 块和 MLP 块共对应两个 layer normalization,其输入合计为 2bsh,中间激活 4bsh
每个 transformer 层中间激活占用显存为 34bsh + 5bs^2a 字节
以 GPT3-175B 模型为例,模型配置如下
- layer(l):96
- hidden size(h):12288
- attention head(a):96
- sequence length(s):2048
假设采用混合精度训练,都采用 bf16 或 fp16 存储,每个元素占2个bytes,则模型参数占用显存为 350 GB
| batch size(b) | 中间激活显存 (34bsh + 5bs^2a)*l | 中间激活显存/模型参数显存 |
|---|---|---|
| 1 | 275 GB | 79% |
| 64 | 17.6 TB | 5000% |
| 128 | 35.3 TB | 10100% |
可以看到中间激活占用显存,可以通过激活值 checkpoint 技术显著减少激活所需的内存,但代价是增加了 0.33 倍重计算
定义 c 为两个激活值 checkpoint 之间的 Transformer 块数量
大型模型如 Turing-NLG 17.2B 和 GPT-3 175B 都是使用该方法进行训练的。存储激活值 checkpoint 所需的内存近似估计为 2bsh * l/c
下图 a 第 7 列是存储激活值 checkpoint 所需的内存
假设 b:32,s:1024,c:1,虽然生成的激活值 checkpoint 比完整的中间激活小几个数量级,但在超过万亿参数时,GPU 内存仍然无法存储所有中间激活值
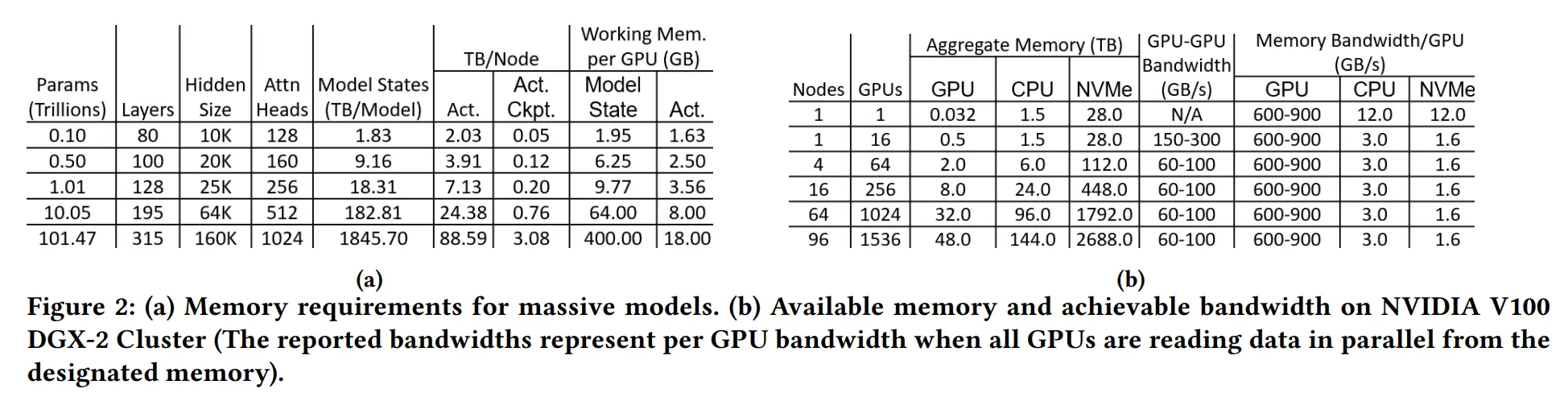
模型状态工作内存 (MSWM)
是在所有模型状态被 offload 至 CPU 或 NVMe 后,在模型中执行前向或 BWD 所需的最小 GPU 内存占用
从上图 (a) 倒数第 2 列得知,在超过 1k 亿个参数后,显存需求激增,在遇到 MLP 中的 linear 申请存储 8h^2+5h 个参数的连续内存时,没有足够的连续空间,下文提出了一种有别于 MP 的方法解决这个问题
激活值工作内存 (AWM)
是在进行 BWD 之前,在 BWD 中重计算激活所需的内存。这取决于两个连续激活值 checkpoint 之间的激活大小
结合上图 (a) 最后 1 列,AWM 由几十个中间激活层参数组成,只要总的 AWM 占用满足显存,不会遇到连续空间不足的问题
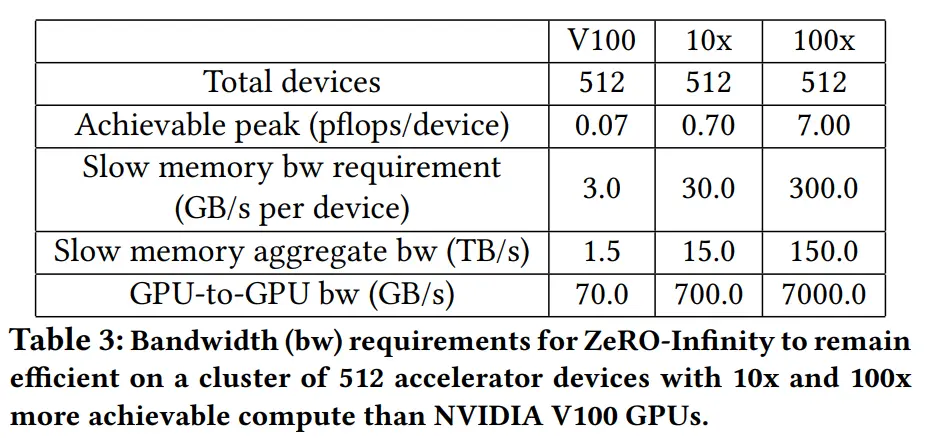
带宽需求
加载 CPU 和 NVMe 内存关键是有限的带宽是否会影响训练效率。文中描述了带宽对训练效率的影响。定义了效率 efficiency
假设没有计算通信重叠,执行工作负载,使用峰值计算吞吐量 penk_tp,数据移动带宽 bw,算术强度 ait 评估训练效率
ait 是总计算量与计算需要移动的数据之间的比率,描述了每次数据移动的计算量,更高的 ait 表示对带宽的要求更低
效率 efficiency 推导如下
Quantifying AIT in DL training
模型状态和激活值 checkpoint 有不同的 ait 值,文中通过每次训练迭代中的总计算量,计算每个模型状态和激活值的数据移动量进行 ait 量化
- 总计算量:每次迭代的总计算量主要取决于 Transformer 中的参数 p,序列长度 s 和 batch size,即 2bsp,BWD 的计算量大约是 FWD 的两倍。此外,激活值 checkpoint 在 BWD 期间需要进行额外的正向计算,所以每次迭代的总计算量为 8 bsp
- 参数和梯度:参数在 FWD 和 BWD 期间至少需要从 CPU 加载到 GPU 两次,存在 2p 的数据移动量,在使用激活值 checkpoint 时,参数可能需要在 BWD 期间进行额外的加载,增加了额外 1p 的数据移动量。此外,梯度必须至少从 GPU 存储到其目标位置一次,增加了最后1p 的数据移动量,假设参数和梯度存储在相同的目标位置,FWD 和 BWD 期间的总数据移动量为 4p,即 8p 字节。每次迭代的总计算量,因此 ait 与参数和梯度的关系为 bs
- 优化器状态:优化器状态至少需要读取和写入一次 GPU,总数据移动量为 2os,约为 216p 字节(结合上文的 adam,笔者认为是 220p 字节),因此在完整的训练迭代过程中,ait 与优化器状态关系为 bs/4
激活值 checkpoint:在 FWD 中,激活值 checkpoint 必须保存到目标位置,并在 BWD 期间检索。总数据移动量与激活值 checkpoint 的关系为 2 bsh l/c,ait 与激活值 checkpoint 的关系为 24hc
Bandwidth Requirements
由于 ait 的变化,模型状态和激活 checkpoint 有非常不同的带宽要求。模型状态仅取决于 bs,激活 checkpoint 取决于 ch
由上面的公式得知,efficiency 的带宽需求还取决于 peak_tp,作者使用 NVIDIA V100 DGX-2 SuperPOD 集群进行了如下实验
实验假设了不在实验变量中的其他通信带宽无限,且 peak_tp 是理论峰值
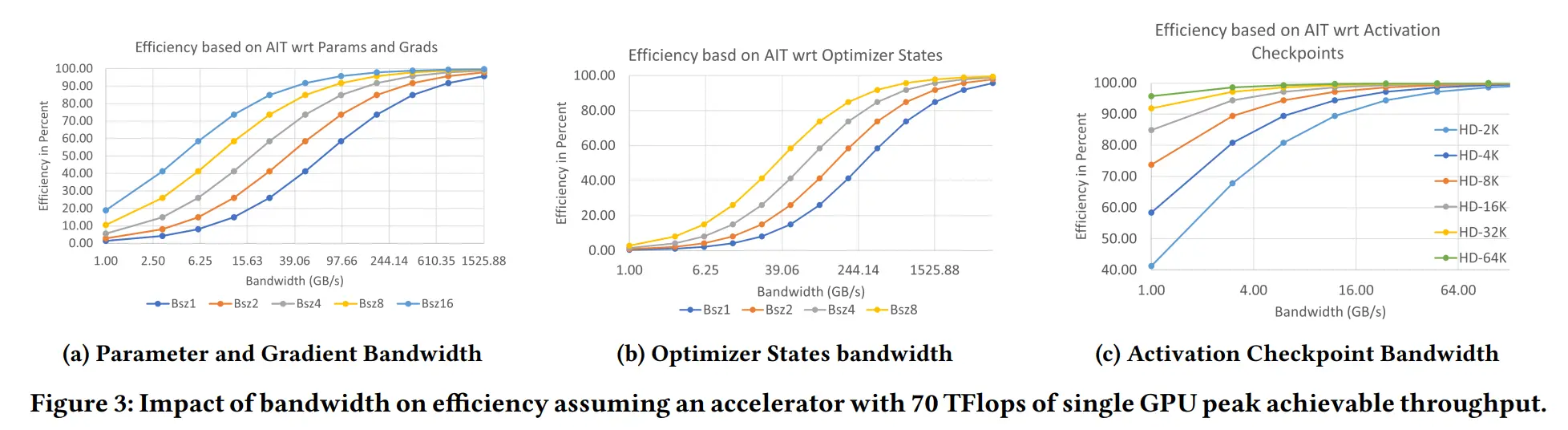
- a:参数和梯度的带宽超过70 GB/s,即使是最小的 batch size,也可以实现50%以上的效率,在这个带宽下,只要 bz 足够大,数据移动可以与计算完全重叠,以实现100%的效率
- b:相比 a,优化器状态需要高出近 4 倍的带宽才能达到 50% 效率。此外,优化器状态在 FWD 和 BWD 结束时更新,并且不能与计算重叠
- c:启用激活值 checkpoint 后,即使 h 为 2k,2GB/s 的带宽也能维持 50% 以上的效率。一旦 h 超过 8k,带宽需求将降至 1 GB/s 以下
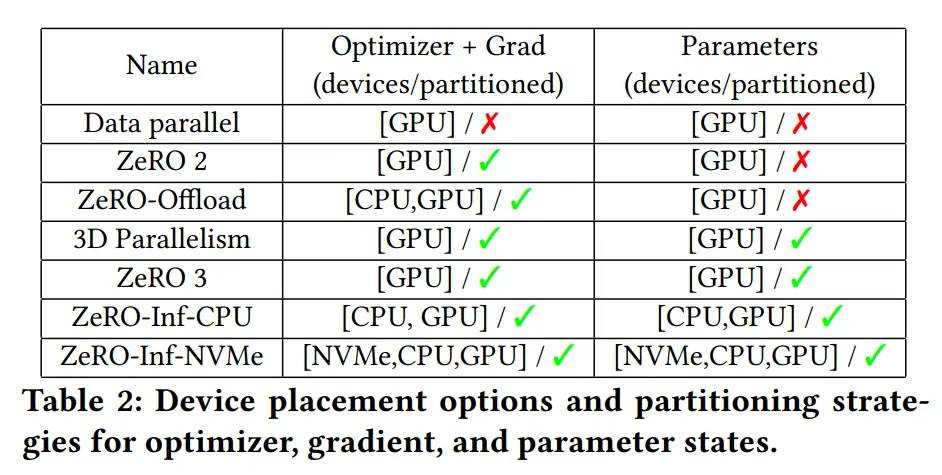
ZeRO-Infinity 设计概览
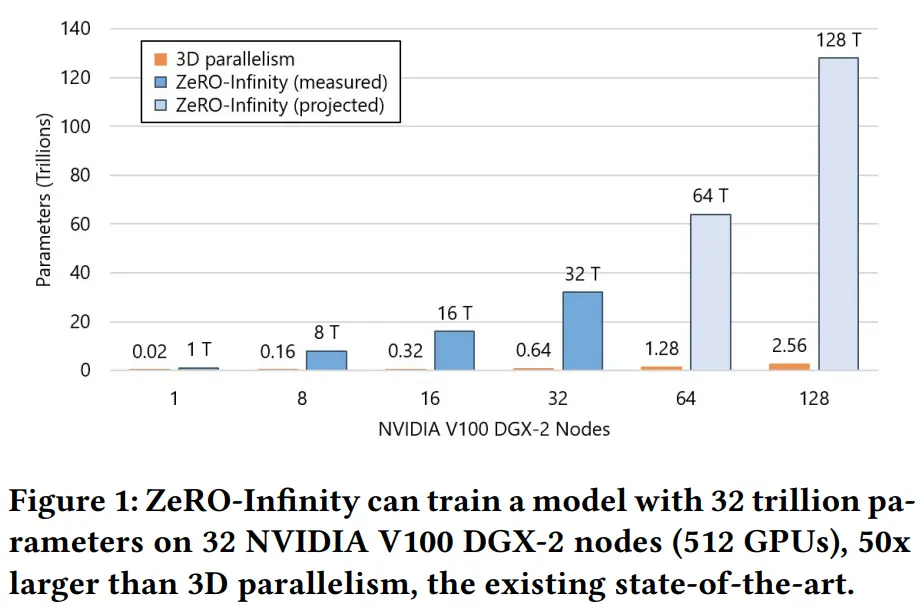
GPU 集群在存储器方面具有高度异构性。除了GPU内存外,还有 CPU 内存以及无限大(Infinity)的 NVMe 磁盘空间。ZeRO-Infinity 通过利用这些异构存储器,突破了 GPU 内存壁垒。下图比较了 3D 并行和 ZeRO-Infinity 所能达到的最大模型规模,其支持每个 NVIDIA V100 DGX-2 节点 1 万亿个参数,相比 3D 并行增加了 50 倍
示意图
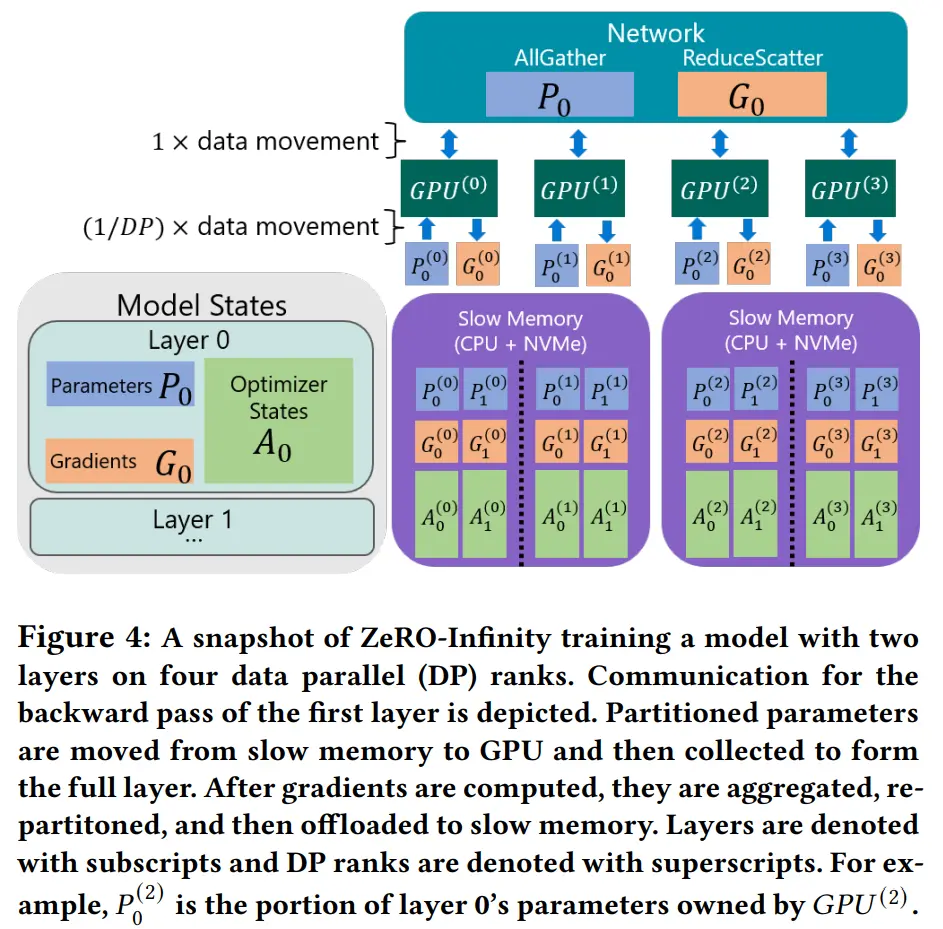
Design for Unprecedented Scale
- Infinity offload engine for model states:ZeRO Infinity 基于 ZeRO-3 设计,对所有模型状态进行分区,消除内存冗余,设计了 Infinity offload engine,将所有分区模型状态 offload 到 CPU 或 NVMe,或者根据内存需求保留在 GPU 上。请注意,上面图 2a 和图 2b 中,96 个节点(1536个GPU)的 DGX-2 集群的总 NVMe 内存足够存储 100 万亿参数模型的模型状态
- CPU Offload for activations:将激活值内存 offload 到 CPU 内存中
- Memory-centric tiling for working memory:ZeRO-Infinity 可以支持任意大小的算子,不依赖 MP,将大型算子分解为由原始算子的参数切片组成的数学上等价的较小线性算子序列,逐个获取和释放每个切片的参数和梯度
Design for Excellent Training Efficiency
问题:带宽不匹配:GPU > CPU > NVMe
必要带宽:
- 参数和梯度:70GB/s
- 优化器状态:1.5TB/s
- 激活值 checkpoint:1-4 GB/s
优化参数和梯度效率
提出了优化两种方案
- 基于带宽的划分策略(没明白,看懂代码后再来更)
- 重叠计算通信
提高优化器状态效率
基于 ZeRO-Offload ,可以利用聚合的 GPU 和 CPU 内存带宽以及聚合的 CPU 计算来进行优化器更新,不同是的,在 NVMe offload 时,需要将数据从 NVMe 传输到 CPU 内存,并以适合 CPU 内存的块大小进行优化器更新,一次一个块地进行,这会受到 NVMe → CPU 带宽的限制,可以多个节点聚合 NVMe 带宽
不足:可能会导致 CPU 内存碎片化(PyTorch 2.0 提出了新的内存碎片整理策略,后面有时间看看)
优化激活值效率
每个 GPU 通过 PCIe 以 3GB/s 的速度并行读写数据到 CPU,可以超过 80% 的效率(对于隐藏大小大于8K),减少激活值 checkpoint 频率也可以提高效率
Design for Ease of Use
不同于 MP,用户不需要在设计模型时考虑能否并行
提出了两个优化策略,后面内容有实现细节
- automated data movement:通过向 PyTorch 子模块注入 FWD/BWD hooks 触发参数的收集和分区操作。在 FWD/BWD 之前,进行 allgather 收集数据。而在 FWD/BWD 之后,通过 hooks 触发参数和梯度的分区,可选择将它们转移到 CPU 或 NVMe
- automated model partitoining:通过包装所有模块类的构造函数,使每个子模块的参数在初始化过程中进行分区和移动
效率优化
下面优化上一节提出的改进点
Bandwidth-Centric Partitioning
ZeRO-Infinity 提出了新的数据映射和检索策略,以解决 NVMe 和 CPU 内存带宽限制的问题
与 ZeRO 和 ZeRO-Offload 不同的是,ZeRO-Infinity 将每个层的参数划分到所有的 DP 进程中,并且在访问参数时使用 allgather 而不是 broadcast,原因如下:
当数据位于 GPU 上时, broadcast 和 allgather 通信成本相同,
但当数据位于 NVMe 或 CPU 时,
- 如果使用 braodcast,由于每个参数完全由一个 DP 进程拥有,参数必须先通过 PCIe 从其源位置传输到 GPU 内存,然后才能 broadcast,在此过程中只有一个 PCIe 可以处于活动状态,而连接到其他所有 GPU 的 PCIe 链路都处于闲置状态
- 如果使用 allgather,所有 PCIe 链路都同时处于活动状态,每个链路传输 1/dp 的参数,这样 CPU/NVMe 与 GPU 之间的通信带宽会随着 dp 线性增长
在大规模训练时,该方法可以提供 Infinity 的异构内存带宽,例如在 64 个 DGX-2 节点上,ZeRO-Infinity 可以获得超过 3TB/s 的 CPU 内存带宽和超过 1.5TB/s 的 NVMe 带宽
Overlap Centric Design
解决在单个 GPU 或单个节点中,带宽仍然可能成为瓶颈的问题。
即使是 GPU 之间的 allgather 通信在小 batch size (图3)下也会对效率产生重大影响
此外,访问 NVMe 内存需要进行三个步骤
- NVMe → CPU
- CPU → GPU
- GPU → GPU (allgather)
如果顺序执行上面步骤,效率会很差。 ZeRO-Infinity 提出了 overlap engine,包括
dynamic prefetcher:在 FWD/BWD 时,要使用参数之前,并行执行参数的移动。实时跟踪 FWD/BWDW,构建每次迭代的算子序列的内部映射,,跟踪算子序列的位置,并行加载即将执行算子的参数,如在执行算子的计算时,对即将执行的 3 个算子依次并行执行 NVMe → CPU,CPU → GPU 和 GPU → GPU。当 FWD/BWD 发生变化时,也可以更新算子序列映射
communication and offload overlapping mechanism:并行执行 BWD 与梯度更新移动。类似上面,在计算 BWD 算子时,对已经执行的 2 个算子依次并行执行梯度更新与 GPU → CPU 梯度传输
Infinity Offload Engine
DeepNVMe
C++ NVMe 读/写库,异步完成的批量读/写请求,,刷新正在进行的读/写的显式同步请求。允许将这些请求与 GPU → GPU 或 GPU → CPU 通信计算重叠
实现了接近峰值的 NVMe 顺序读写带宽,包括对 I/O 请求的并行化,智能工作调度,避免数据复制和内存固定
Pinned memory management layer
确保 NVMe → CPU 读/写 高性能的数据,数据必须保存在固定内存缓冲区中。该层通过重复使用少量(数十GB)的内存来管理有限的固定内存供应,以将整个模型状态(数十TB) offload 到 CPU/NVMe。
内存缓冲区重复使用可防止 CPU/GPU 内存碎片化,还为 PyTorch 数据提供具有固定内存数据的功能,允许在原始地址计算,然后将其写入 NVMe,无需进一步复制以提高带宽
实现细节
ZeRO Infinity 基于 PyTorch 代码实现,并且不用重构任何模型代码
Automating Data Movement
ZeRO-Infinity 需要协调模型参数、梯度和优化器状态数据移动,必须确保这些数据在被使用前移动到 GPU 内存中,并在使用之后重新分配位置
PyTorch 模型以层级模块的形式表示,代表着神经网络的各个层次。例如,Transformer 架构中包含了诸如自注意力和前馈网络等子模块。自注意力子模块又包含了线性层和其他子模块
ZeRO-Infinity 会递归地向模型的子模块中插入 hooks ,以自动化所需的数据移动。在子模块的 FWD 开始时,这些 hooks 会确保子模块的参数可用于计算,否则它们将执行 allgather 操作,并阻塞到参数可用
类似上文介绍的基于重叠的设计,在子模块的 FWD/BWD 结束时,再次对参数进行分区,并可选择将其转移,减少参数通信时的阻塞
Auto Registration of External Parameters
在理想情况下,一个子模块的参数和梯度只在自己的 FWD/BWD 中使用,这样可以很容易地识别并自动化数据移动,但某些模型架构例外,其中在一个子模块中定义和分配的参数在不同子模块的 FWD/BWD 中都被使用
例如,GPT 等模型在网络的开头和结尾都共享 embedding 层的权重
将上面这种跨模块边界使用的参数称为外部参数,这很难知道在一个子模块的 FWD/BWD 的开始时应该收集哪些参数
于是提出了将外部参数手动注册到 ZeRO-Infinity 中,以便在访问它们的子模块的 FWD/BWD 中进行 gather,注册后,外部参数将像其他参数一样,将被包含在 dynamic prefetcher 中
此外还提供了检测这些场景并自动注册外部参数机制,不用更改任何代码
- 截获分区参数访问:PyTorch 模块将其数据参数存储在哈希表中。在初始化时,使用子类类型替换哈希表,覆盖数据的访问方法。当访问一个分区参数时,对该参数进行阻塞的 allgather,将其注册为外部参数,然后返回收集到的参数
- 激活信息检测:子模块的 FWD 可能会返回一个参数,供另一个子模块的 FWD/BWD 使用。例如,Megatron-LM 中线性层 FWD 后返回 bias,在父 Transformer 层模块中使用,再检查每个子模块 FWD 返回的激活值输出中是否包含分区参数,如果包含,则对其进行收集和注册,作为外部参数
Automatic Model Partitioning during Initialization
需要在初始化时划分模型的每个层对应的参数,而不是在整个模型初始化之后再进行划分,以节省峰值内存
提供了一个 Python ZeRO-Infinity 上下文,用于修饰 torch.nn.Module 的 init 方法,在每个模块初始化之后,立即将其分配的参数划分在所在进程组中
只有单独的子模块在完全初始化之后才会被划分,整个模型不会在所有并行进程上复制。一个拥有 5 千亿个参数的模型只需要 1TB 的聚合 CPU 内存就可以在初始化期间完全划分
实验
配置
集群:V100 SXM3 32 GB GPU * 512
通信带宽:800 Gbps
no MP benchmark:torch DDP
MP benchmark:Megatron-LM
模型:GPT(s = 1024)
模型配置如下
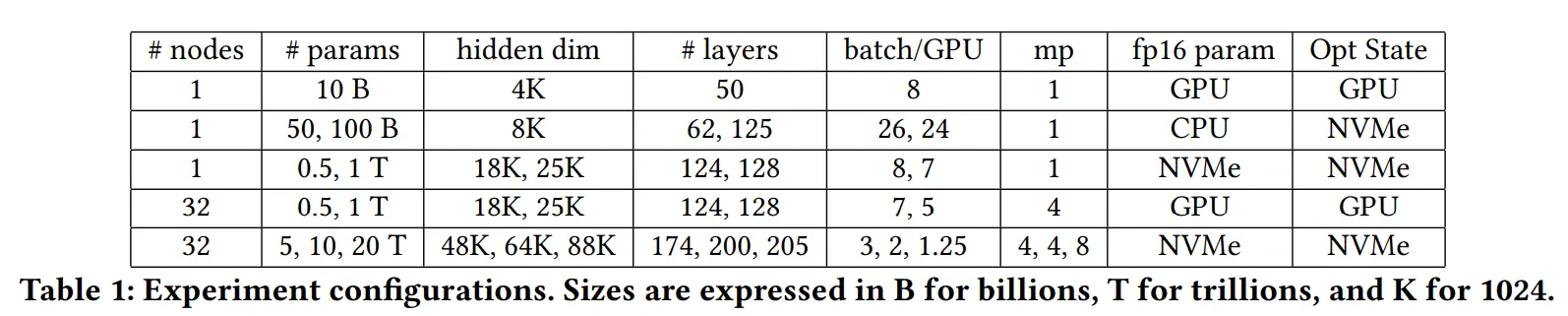
Model Size
Infinity:32 万亿参数
3D 并行:6500 亿参数
图5a,提升 50 倍
Model Speed
Infinity 训练 20 万亿参数时,与 3D 并行有几乎相同的吞吐量
进一步增加模型大小,由于3D并行的内存限制,会 OOM,而 Infinity 吞吐量为 49 TFlops/GPU
在极限情况下,由于 CPU 内存有限,导致每个 GPU 的 batch size 非常小,图5a显示性能下降,可以通过增加 CPU 内存或者将激活值 checkpoint 转移到 NVMe 中改善
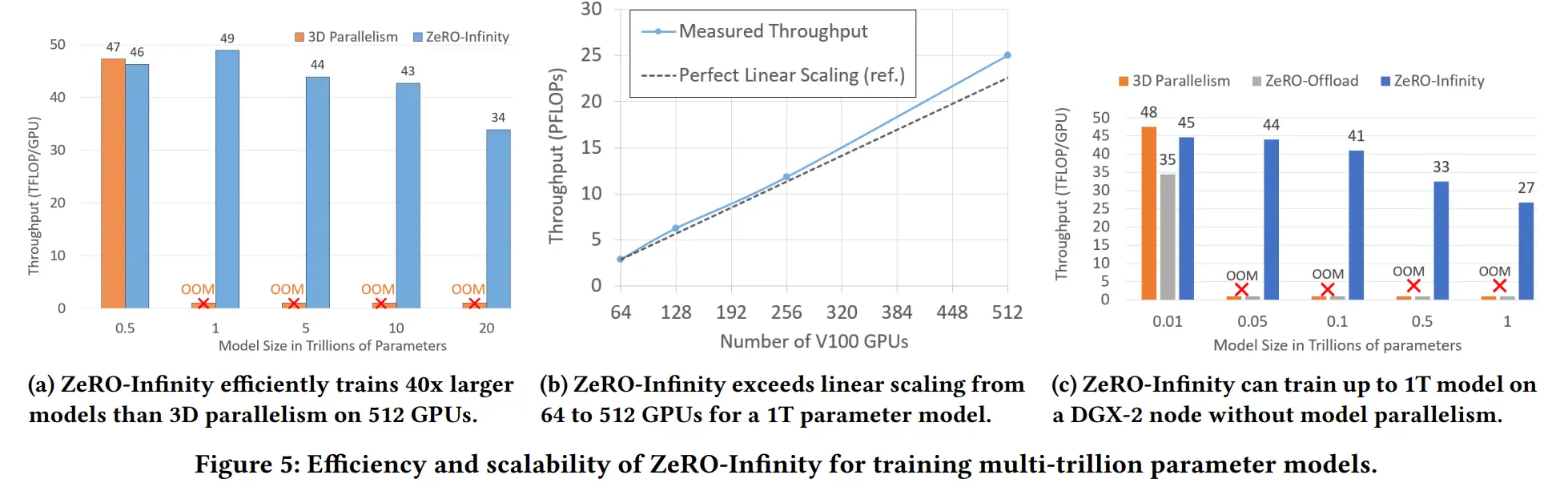
Superlinear Scalability
通过有效利用聚合 PCIe 和 NVMe 带宽的线性增加加速参数和优化器状态的 offload,并利用额外节点的 CPU 计算进行参数更新,实现超线性扩展(图5b)
即使规模较小时,ZeRO-Infinity 也只需 4 个节点就实现了超过 2.8 petaflops,44 Tflops/GPU,聚合 NVMe 不高的带宽足够用于 Infinity
Democratizing Large Model Training
图5c 在单个节点,16个 GPU 上,使用 Infinity 可以训练超过1万亿参数,27 TFlops/GPU,3D并行和 ZeRO-Offload 无法训练超过 200 亿参数
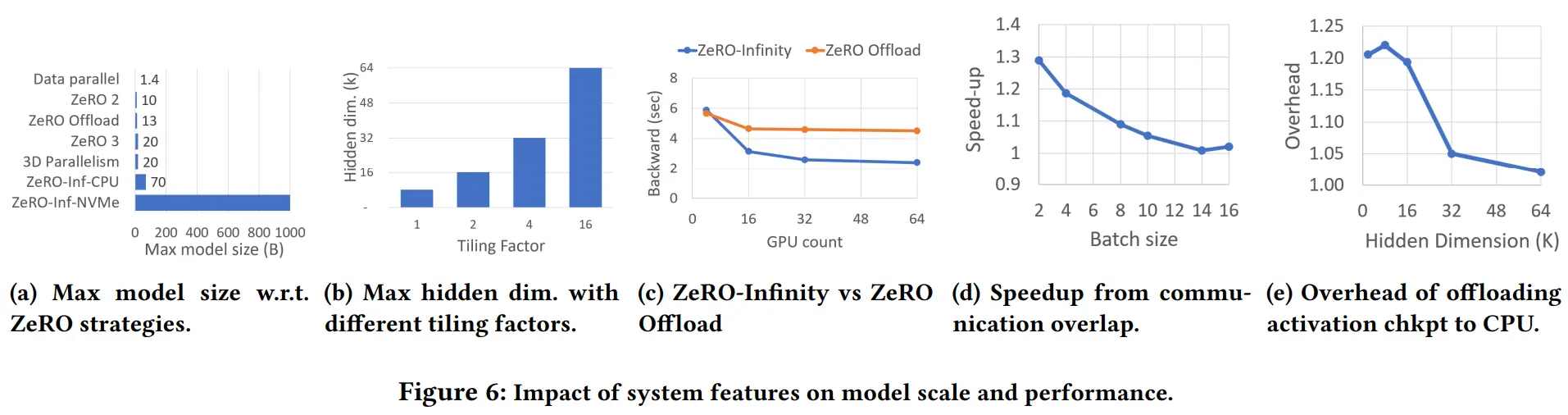
Impact of System Features on Model Scale
图6a 对比了不同策略,利用不同设备在单节点训练时能达到的最大参数量
利用 CPU:70B
利用 CPU + NVMe:1T
通过将总 GPU 内存预先分割成 2GB 的连续块,使得所有大于2GB的内存分配请求都将失败,以此测试最大 hidden size
图6b memory-centric tiling 系数为 16 时可训练 64k 的最大 hidden size
Impact of System Features on Performance
图6c 比较了使用 Infinity 和 Offload 将梯度卸载到 CPU 内存对 8B 模型的 BWD 时间的影响,Offload 受限于单个 PCIe 带宽,在 64 GPU时,只有 Infinity 50% 的速度
图6d 比较了重叠通信与否对速度的影响,bz 越大,重叠通信的影响越小
图6e 比较了 offload 不同规模的 hidden 层 checkpoint 到 CPU 的收益,hidden size 越大收益越小
结论
带宽是制约计算能力的一大关键因素,Infinity 在利用 CPU 和 NVMe 设备的同时,聚合所有通信设备的带宽提速