摘要
讲解 CUDA 内存层次结构,如寄存器,共享内存,纹理内存,全局内存等。
内存层次结构
首先了解一下应用程序遵循的局部性原则
时间局部性
一个内存地址被访问,那么这个内存地址很可能会被多次访问,被访问的概率会随着时间逐渐降低
空间局部性
如果一个内存地址被访问,那么附近的地址也有可能被访问
随着科技的发展,更低延时和低容量的内存层次结构被设计出来以提高计算机性能,内存结构变得复杂,诞生出了由多级带宽,容量组成的内存层次结构,如下图所示
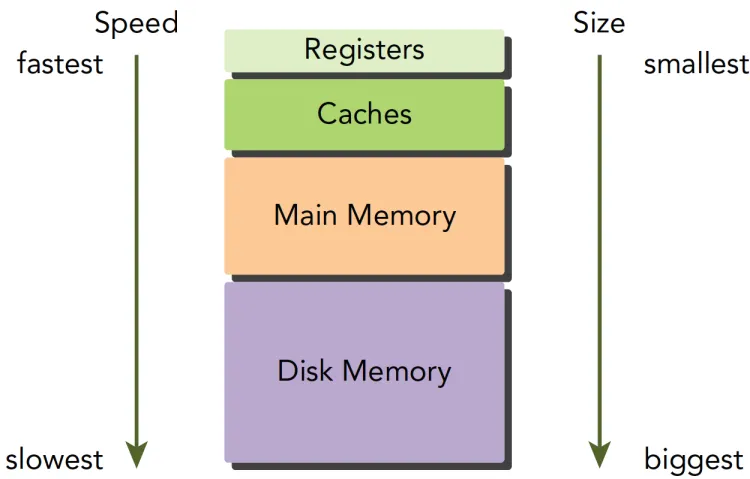
上述结构从下往上有如下特点
- 更高的成本/bit
- 更低的容量
- 更低的延时
- 更高的访问频率
CPU 的主存采用动态随机存储器(DRAM),更快的 CPU 一级缓存使用的是静态随机存储器(SRAM),当数据被频繁使用时,会保存在低延时、低容量的内存层次中,否则会保存在高延时,大容量的容器中。GPU 的主存和 CPU 一样使用 DRAM,内存层次结构也非常相似,与 CPU 内存模型不同的是,通过 CUDA,我们可以方便地控制 GPU 的内存
CUDA 内存模型
CUDA 提供了多种可编程的不同类型的内存可以满足不同的计算需求。每种内存类型都有其特定的用途和性能特点
- 寄存器(Registers)
- 共享内存(Shared Memory)
- 本地内存(Local Memory)
- 常量内存(Constant Memory)
- 纹理内存(Texture Memory)
- 全局内存(Global Memory)
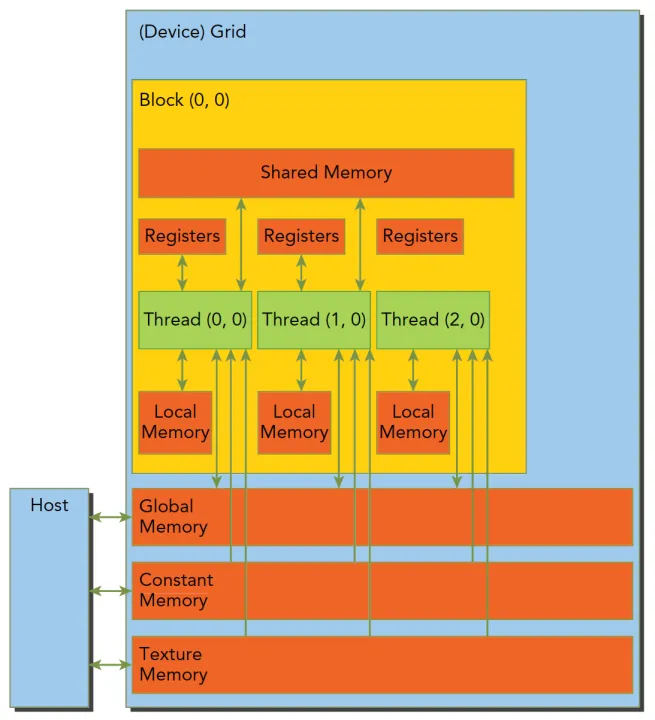
如上图所示,每个核函数都有自己私有的本地内存,每个线程块有自己的共享内存,对同一线程块中所有的线程可见,其内容会持续线程块的整个生命周期。所有线程都可以访问全局内存。所有线程对常量内存和纹理内存都只读
在内存层次结构中,纹理内存为各种数据布局提供了不同的寻址模式和滤波模式,对于应用程序来说,全局内存、常量内存中的内容具有相同的生命周期
寄存器
寄存器是一种低容量、超高速度的内存类型,每个线程都可以使用寄存器来存储临时数据。当在核函数内的自变量没有其他修饰符,该变量就存储在寄存器中,在核函数中定义的的数组也存储在寄存器中
寄存器对于每个线程是私有的,核函数使用寄存器来通常保存被频繁使用的线程私有变量,寄存器变量的声明周期和核函数一致,执行完毕后,寄存器就不能访问了。
寄存器是 SM 中的较少资源,Fermi 架构中每个线程最多63个寄存器。Kepler结构扩展到255个寄存器,一个线程如果使用更少的寄存器,那么就会有更多的常驻线程块,SM上并发的线程块越多,效率越高,性能和使用率也就越高。
可以使用如下命令得到每个核函数运行时使用的寄存器数量、共享内存字节数以及每个线程所使用的常量内存和字节数
1 | nvcc -Xptxas -v *.cu |
以第三章中的矩阵乘法和加法为例,输出表示编译器进行了两个操作:编译矩阵乘法函数Z9MatrixMulP6MatrixS0_S0和矩阵加法函数Z9MatrixAddP6MatrixS0_S0,分别针对sm_52架构,对于每个函数,都会输出函数属性,如堆栈帧大小、溢出存储和溢出加载的大小,并且报告使用的寄存器数量和全局内存cmem[0]大小
1 | ptxas info : 0 bytes gmem |
如果一个核函数使用了超过硬件数量的寄存器,会用本地内存代替多占用的寄存器。nvcc 会使用启发式策略来最小化寄存器的使用,为了避免寄存器溢出,可以在核函数的代码中配置额外的信息来辅助编译器优化,下面代码中的maxThreadsPerBlock意为每个块最多可以启动的线程数量,minBlocksPerMultiprocessor意为每个 SM 最少运行的线程块数量
1 | __global__ void __launch_bounds__ (maxThreadsPerBlock, minBlocksPerMultiprocessor) |
在调用下面的核函数时,最多可以使用 1024 个线程来执行该内核函数,在每个 SM 最少运行的线程块数量为 1
1 | __global__ void __launch_bounds__ (1024, 1) MatrixAdd(Matrix *A, Matrix *B, Matrix *C) { |
还可以在编译时使用-maxrregcount来控制一个编译单元里所有核函数使用的寄存器的最大数量,但这可能会和__launch_bounds__产生冲突,如果使用-maxrregcount参数限制每个线程使用的寄存器数量为32,并且使用__launch_bounds__属性限制每个块可以启动的线程数量为1024,那么每个块中实际可以启动的线程数量就会受到限制,只能启动32个线程
本地内存
本地内存是每个线程私有的内存空间,用来存储线程私有的临时数据。核函数中符合存储在寄存器中但不能进入被核函数分配的寄存器空间中的变量将存储在本地内存中,以下几种变量可能存放在本地内存中的
- 使用未知索引引用的本地数组
- 可能会占用大量寄存器空间的较大本地数组或者结构体
- 任何不满足核函数寄存器限定条件的变量
本地内存本质上和全局内存存储在同一块存储区域,但本地内存为每个线程私有,且会比访问全局内存更快,对于2.0以上的设备,本地内存存储在每个 SM 的一级缓存和设备的二级缓存上
共享内存
共享内存是一种由多个线程共同使用的内存,是线程之间相互通信的基本方式,用来存储临时数据和高频使用的数据。共享内存类似于 CPU 的一级缓存,但可被编程。每个 SM 都有一些由线程块分配的共享内存,因此,不能过度使用共享内存,否则可能会限制活跃线程束的数量。
共享内存在核函数内声明,生命周期和线程块一致,线程块运行开始,此块的共享内存被分配,当此块结束,则共享内存被释放
可以通过在核函数中使用__shared__修饰符将变量放在共享内存中
因为共享内存是线程块中线程都可以访问,且线程是并发执行的,所以当同一个线程块中的多个线程访问同一个内存地址时可能会发生以下情况
- 线程 a 和线程 b 同时将同一数组中的数据拷贝到共享内存中,导致数据冲突
- 线程 a 和线程 b 同时计算 x 和 y 数组对应位置的和,并将结果存储到 z 数组中,导致结果不正确
所以访问共享内存前必须使用如下的同步语句
1 | void __syncthreads(); |
如果频繁使用以上语句让 SM 进入空闲状态,会影响性能
SM中的一级缓存和共享内存共享片上内存,片上内存(on-chip memory)是指位于GPU片上的内存,即与 SM 处理器相连的内存,包括一级缓存、共享内存和常量缓存等
片上内存的大小根据 SM 版本而不同,以本人电脑的 sm_52 版本为例,一级缓存和共享内存共享的片上内存大小默认为
- 一级缓存:64KB
- 共享内存:32KB
因此,sm_52 版本的 SM 中共享的片上内存大小为 64KB + 32KB = 96KB,默认通过静态划分,运行时可以通过下面语句进行设置分配方案
1 | cudaError_t cudaFuncSetCacheConfig(const void * func,enum cudaFuncCache cacheConfig); |
func: 指向内核函数的指针,表示需要设置缓存配置的内核函数cudaFuncCache: 表示内核函数的缓存配置,可以是以下值之一cudaFuncCachePreferNone: 表示不使用缓存cudaFuncCachePreferShared: 表示优先使用共享内存cudaFuncCachePreferL1: 表示优先使用一级缓存cudaFuncCachePreferEqual: 表示优先使用 L1 缓存或共享内存,取决于哪个更快,使用该选项可能会带来额外的性能开销,不建议使用
下面的程序定义了一个用于设置缓存配置的函数cudaFuncSetCacheConfig,它接受一个指向CUDA函数的指针、一个预定义的缓存配置枚举值、一个备选的缓存配置枚举值作为参数,并返回一个错误码,还定义了一个空的内核函数Kernel_func用于演示
1 |
|
常量内存
常量内存驻留在设备内存中,每个SM都有专用的常量内存缓存,可以通过在核函数中使用__constant__修饰符将变量放在常量内存中
常量内存需要在核函数外,全局范围内声明,对于所有设备,只可以声明 64KB 的常量内存,常量内存是静态声明的,主机端代码可以初始化常量内存,初始化后不能被核函数修改,并且对同一编译单元中的所有核函数可见,相关函数将数据从主内存复制到常量缓存(constant memory)
1 | cudaError_t cudaMemcpyToSymbol(const void* symbol,const void *src,size_t count); |
symbol: 指向常量缓存的指针,常量缓存是一种特殊的内存类型,用于存储在编译时不变的变量src: 指向主内存中的数据的指针,要复制的数据必须位于主内存中,因为SM处理器无法直接访问主内存count: 要复制的数据的字节数
下面的程序在常量内存中定义了一个名为 a 的常量数组,并通过 cudaMemcpyToSymbol 函数将一个主机上的数组 h_a 复制到该常量数组中
1 |
|
纹理内存
纹理内存是一种用来存储纹理数据的内存类型,在每个 SM 的只读缓存中缓存,纹理内存是通过指定的缓存访问的全局内存,只读缓存包括硬件滤波的支持,它可以将浮点插入作为读取过程中的一部分来执行,纹理内存是对二维空间局部性的优化,所以通常用来存储渲染图像和视频的数据,同时对于某些需要滤波的程序性能更好,可以直接通过硬件完成计算
定义一个 CUDA 纹理对象需要使用cudaCreateTextureObject 函数,解释如下
1 | cudaError_t cudaCreateTextureObject( |
pTexObject:指向一个cudaTextureObject_t类型的指针,用于存储新创建的纹理对象pResDesc:指向一个cudaResourceDesc类型的指针,用于描述纹理资源pTexDesc:指向一个cudaTextureDesc类型的指针,用于描述纹理对象的属性pResViewDesc:指向一个cudaResourceViewDesc类型的指针,用于描述纹理视图的属性
更具体的解释请看官方文档
下面的代码创建了一个二维数据简单地模拟图像使用纹理内存
1 |
|
纹理内存这部分知识点偏多,后面有机会和大家细细道来
全局内存
全局内存也可以说是 GPU 的主存。它是 GPU 内存层次结构中最大容量、最高延时的内存类型,它的声明可以在所有 SM 设备上被访问到,并且与程序同生命周期,全局变量支持静态声明和动态声明
可以通过在核函数中使用__device__修饰符将变量放在全局内存中
我们在第三章中的所有程序在 GPU 上访问的内存都是全局内存,因为线程的执行不能跨线程块同步,当有多个线程并发地修改全局内存的同一位置时,会导致未定义的程序行为
全局内存访问必须是自然对齐的,也就是一次要读取 32 的整数倍字节的内存,所以当线程束执行内存加载或存储时,需要满足的传输数量通常取决于
- 跨线程的内存地址分布
- 内存事务的对齐方式。
一般满足内存请求的事务越多,未使用的字节被传输的可能性越大,数据吞吐量就会降低,也可以说,对齐的读写模式使得不需要的数据也被传输,所以,利用率低到时吞吐量下降。过去的设备因为没有足够的缓存,对内存访问要求非常严格,现在要求宽松了一些
GPU 缓存
在 CUDA 中,GPU 缓存是不可编程的内存,有如下四种缓存
- 一级缓存
- 二级缓存
- 只读常量缓存
- 只读纹理缓存
每个 SM 都有一个一级缓存,所有 SM 公用一个二级缓存,一级和二级缓存都被用来存储本地内存和全局内存中的数据,也包括寄存器溢出的部分。CUDA 允许我们配置读操作的数据是使用一级缓存和二级缓存,还是只使用二级缓存
CPU 读写过程都有可能被缓存,与 CPU 不同的是,GPU 写的过程不被缓存,只有读取会被缓存,每个 SM 有一个只读常量缓存,只读纹理缓存,它们用于设备内存中提高来自于各自内存空间内的读取性能
CUDA 变量声明总结
下面总结了 CUDA 变量声明和它们相应的存储位置、作用域、生命周期和修饰符
| 修饰符 | 变量名称 | 存储器 | 作用域 | 生命周期 |
|---|---|---|---|---|
float var | 寄存器 | 线程 | 线程 | |
float var[100] | 本地 | 线程 | 线程 | |
__shared__ | float var + | 共享 | 块 | 块 |
__device__ | float var + | 全局 | 全局 | 应用程序 |
__constant__ | float var + | 常量 | 全局 | 应用程序 |
float var +表示标量或数组
下面总结了各类存储器的主要特征
| 存储器 | 片上/片外 | 缓存 | 存取 | 范围 | 生命周期 |
|---|---|---|---|---|---|
| 寄存器 | 片上 | N/A | R/W | 一个线程 | 线程 |
| 本地 | 片外 | + | R/W | 一个线程 | 线程 |
| 共享 | 片上 | N/A | R/W | 块内所有线程 | 块 |
| 全局 | 片外 | + | R/W | 所有线程 + 主机 | 主机配置 |
| 常量 | 片外 | Yes | R | 所有线程 + 主机 | 主机配置 |
| 纹理 | 片外 | Yes | R | 所有线程 + 主机 | 主机配置 |
+表示计算能力在 2.X 以上的 GPU 支持
静态全局内存
我们在第三章中使用 cudaMalloc 函数申请的都是动态内存,也就是动态分配,在 CUDA 中也支持静态内存,也可以说是静态分配,与动态分配相同,需要显式的将内存拷贝到设备端,需要使用的函数如下
1 | __host__ cudaError_t cudaMemcpyToSymbol ( const void* symbol, const void* src, size_t count, size_t offset = 0, cudaMemcpyKind kind = cudaMemcpyHostToDevice ) |
从 CPU 内存中的变量值复制到 GPU 的全局内存中
symbol: 要复制数据的标识符,指的是定义在 GPU 的全局内存中的变量,不是变量地址src: 源数据的地址count: 要复制的数据的字节数offset: 目标标识符中的偏移量,表示从符号的哪个位置开始复制数据kind: 复制数据的类型,可以是cudaMemcpyHostToDevice或cudaMemcpyDeviceToHost
1 | __host__ cudaError_t cudaMemcpyFromSymbol ( void* dst, const void* symbol, size_t count, size_t offset = 0, cudaMemcpyKind kind = cudaMemcpyDeviceToHost ) |
将 GPU 的全局内存中的变量值复制到 CPU 内存中
- dst:目标数据的地址
- symbol:要复制数据的标识符,指的是定义在 GPU 的全局内存中的变量,不是变量地址
- count:要复制的数据的字节数
- offset:源标识符中的偏移量,表示从符号的哪个位置开始复制数据
- kind:复制数据的类型,可以是
cudaMemcpyHostToDevice或cudaMemcpyDeviceToHost
举例程序如下
1 |
|
在以上代码中,如果使用如下代码拷贝是无效的,因为动态拷贝的方法无法对静态变量赋值
1 | cudaMemcpy(&value,devData,sizeof(float)); |
但是可以使用 cudaGetSymbolAddress 函数获取设备的全局变量的地址,而不能使用 & 直接取地址,之后 再使用 cudaMemcpy 将值拷贝到主机上
1 | float *dptr=NULL; |
有一个例外,CUDA 固定内存可以直接从主机引用 GPU 内存,下一章节我们将详细了解