摘要
本文提出的 DistributedDataParallel 在优化器运行之前进行梯度平均,用相同的梯度集更新所有模型副本,这样在数学上和本地训练完全等价,而且可以实现异步,比参数平均更加高效。
paper: https://arxiv.org/abs/2006.15704
code: https://github.com/pytorch/pytorch/
背景
PyTorch 训练流程
- Forward pass:计算损失
- Backward pass:计算梯度
- Optimizer step:更新参数
- 数据并行
PyTorch 有以下方式进行分布式训练,如
- DataParallel:单机多卡进行单进程多线程数据并行训练
- DistributedDataParallel:多机多卡进行多进程数据并行训练
- RPC(e.g. 参数服务器):分布式模型并行训练
另一种方案:参数平均计算所有模型权重的均值,但是当优化器中有依赖过去局部梯度的值(如 Adam 中的动量),优化器的状态可能会逐渐偏离,最终导致训练效果下降。另外,向后传递和参数平均不能重叠运行,浪费了性能
本文提出的 DistributedDataParallel 在优化器运行之前进行梯度平均,用相同的梯度集更新所有模型副本,这样在数学上和本地训练完全等价,而且可以实现异步,比参数平均更加高效
AllReduce
次级实现
每个进程将其输入张量广播给所有对等进程,然后独立地应用算术运算,然而效率不高
于是 Nvidia 在 NCCL 后端中提出了基于环的 AllReduce 和基于树的 AllReduce
AllReduce 操作需要等待所有进程就绪后才能运行,是同步操作,而参数服务器中使用 P2P 通信
系统设计
API 实现
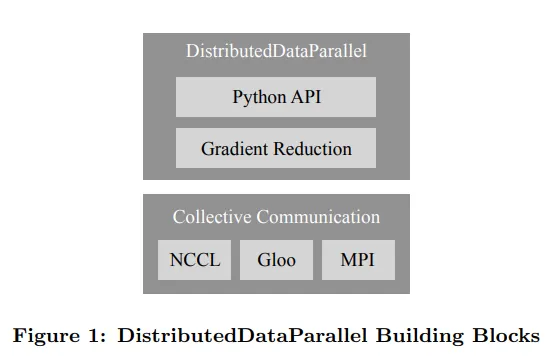
分布式训练时只需要修改少部分训练脚本
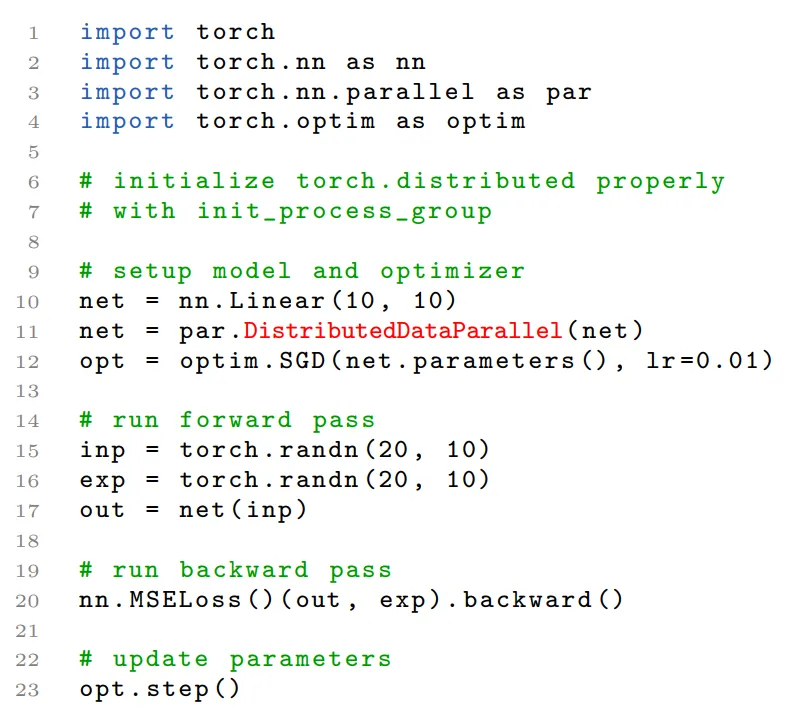
暴露更多接口以实现拦截信号和触发操作的机制进行优化
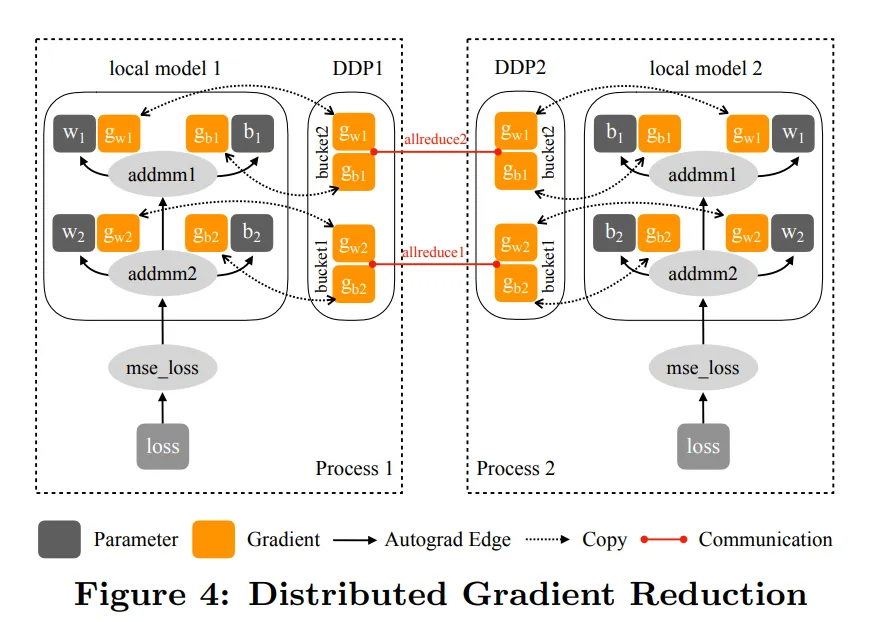
梯度规约
次级实现(All Reduce)
DDP控制所有的训练进程
在模型初始化时广播网络状态,让所有模型以相同状态开始训练
每次迭代时在局部 backward() 之后和优化器 step() 之前执行梯度,以相同的梯度更新权重
DDP 可以注册 autograd hooks,每次 backward() 后触发以下操作
- hooks 扫描所有局部模型参数
- 从每个参数中检索梯度张量
- 再使用 AllReduce 集体通信计算所有进程中参数的平均梯度
- 将结果返回梯度张量
但是有两个性能问题
- 在小 tensor 上的集合通信效率非常低
- 把梯度计算和同步分开之后,不能让它们通信重叠
梯度桶
下图显示了不同的参数规模在执行 All Reduce 时的效率,可以看到 tensor 越大,效率越高
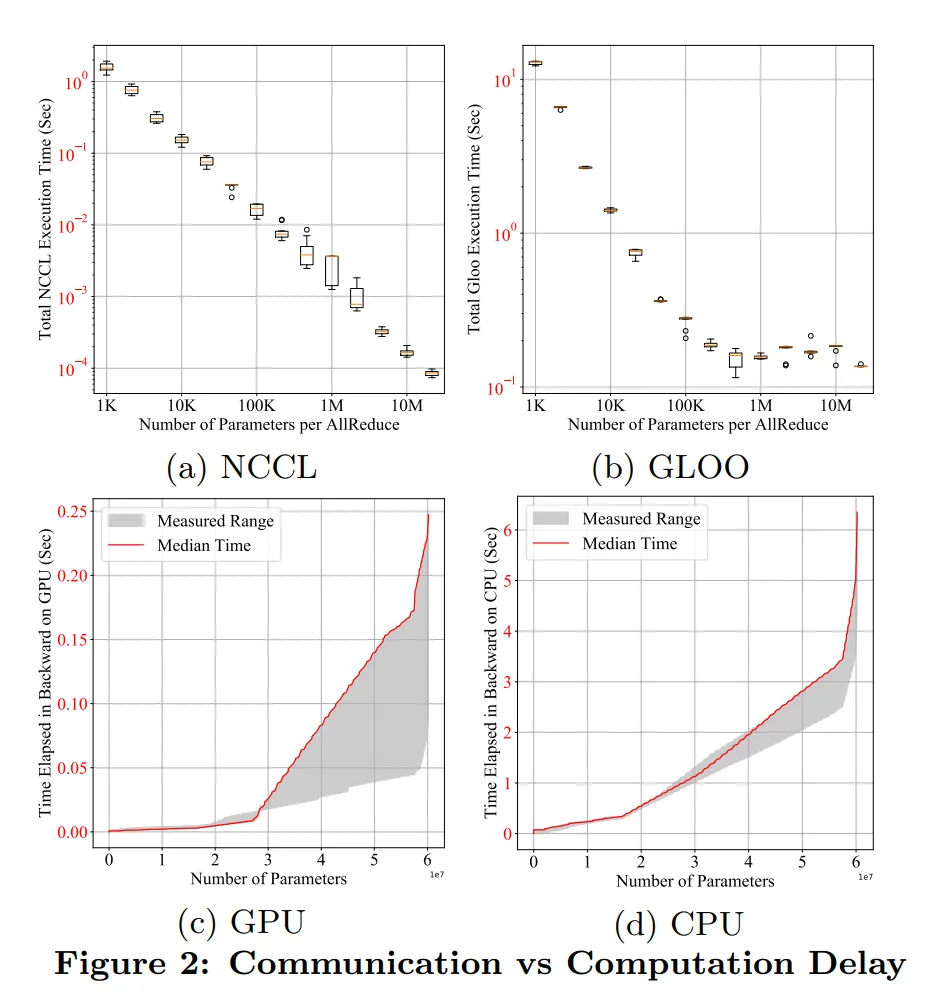
梯度桶为了解决 All Reduce 在小 tensor 上的性能问题,将多个小 tensor 收集为一个桶,在达到一定规模后进行 All Reduce,这将 All Reduce 的操作转变为了异步
通信和计算重叠
在没有使用梯度桶机制之前,通信和梯度计算可以重叠。
在梯度桶机制下,需要等在同一个桶内的所有梯度都计算完成后,才能进行通信。为了重叠,PyTorch 引入 hook 机制,在反向传播计算完成后,调用自定义函数

每当一个梯度计算完成后,对应的 hook 将会被触发,当在同一个bucket中的梯度的hook都被fire后,就调用AllReduce对该bucket进行通信
但是这种策略会导致两个问题
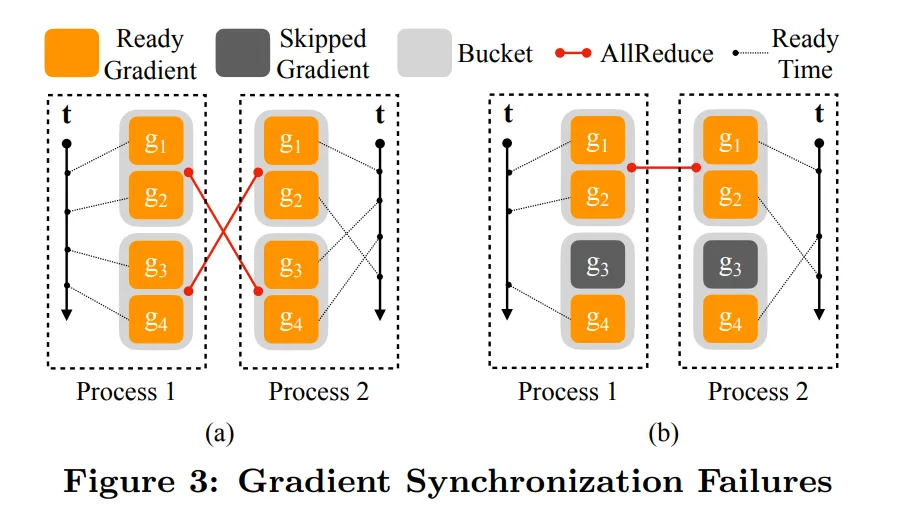
每个进程都是独立的,不能保证所有进程处理桶的顺序一致,如下图 (a) 所示
解决方法:将模型参数的反序作为桶的顺序,反向顺序可以近似表示反向传递中的梯度计算顺序
在某些阶段,网络中的一些层的梯度可以不需要使用,如 Dropout 等,这样这个层对应梯度的 hook 永远不会被触发,如下图 (b) 所示
解决方法:在前向传播结束后从输出开始遍历计算图,使用 bitmap(用于表示二进制数据的数据结构) 记录哪些参数参与计算,哪些参数没有参与计算,对于没有参与计算的参数,标记为 ready
梯度累积
传统梯度传播频率是在每次训练完成后传播,PyTorch 通过在在全局同步梯度之前进行 n 次局部训练迭代,减少梯度通信的时间,这种思路还可以解决大 batch size 占用资源过大的问题,可以将一个batch切分为多个micro
batch,在最后一个micro batch训练完成后,进行梯度更新
但是这种策略会导致某些迭代中没有参与计算的梯度(如 Dropout)和正常计算的梯度混合后,会导致有部分梯度在某些迭代中被累加,而在其他迭代中被清零,PyTorch也无法判断哪些梯度计算完成后立即进行同步,还是等
累加若干个迭代之后再进行同步
解决方法:提出了 “no_sync”上下文。当进行梯度累积并使用 “no_sync”上下文时,会有一些参数在某些迭代中未被使用,但在其他迭代中被使用。为了确保这些未使用参数的梯度不会在下一次迭代中被误用,使用 “bitmap”
来记录这些未使用参数的信息。在进入”no_sync”上下文之后,所有的 DDP hook 都被禁用,这意味着参数的梯度将被累积而不会在该上下文中进行通信。同时,全局未使用参数的信息也会被记录在 “bitmap” 中。这样,在下
一次通信时,PyTorch会使用 “bitmap” 来指导梯度通信,以确保未使用的参数不会被传输,从而保持梯度的正确性。

集合通信
PyTorch DDP 支持三种通讯库:NCCL,Gloo 和 MPI。这些库被包装到同一个 ProcessGroup API 中,在运行多个 ProcessGroup 时,会使用轮询调度将集体通信分派给各个 ProcessGroup 实例,获得更高的带宽利用率
工程实现
python 前后端
可配置参数
- Process Group:指定进程组运行 AllReduce
- bucket_cap_mb:调整桶大小优化训练速度
find_unused_parameters:控制 DDP 是否应该通过遍历计算图来检测未使用的参数
Model Buffers:在某些层中,例如BatchNorm层,需要维护一些状态,比如running variance(运行方差)和running mean(运行均值)。这些状态需要在训练过程中持续更新和使用,以确保模型在训练过程中的稳定性和性能。为了正确处理Model Buffers的同步和广播。DDP通过指定 rank 0 进程来处理。在启用no sync模式时,相应地调整缓冲区的广播,确保所有进程在进行本地计算之前,都拥有最新的Model Buffers的值
梯度规约的重点实现
参数与桶的映射:确保同一 bucket 中的 parameter 都来自同一个device
Autograd Hook:通过为每个桶添加值为梯度数量的递减计数器来判断当前 backward 到了第几层,从而在合适的时候 AllReduce,在下一次前向传播时,重置计数器
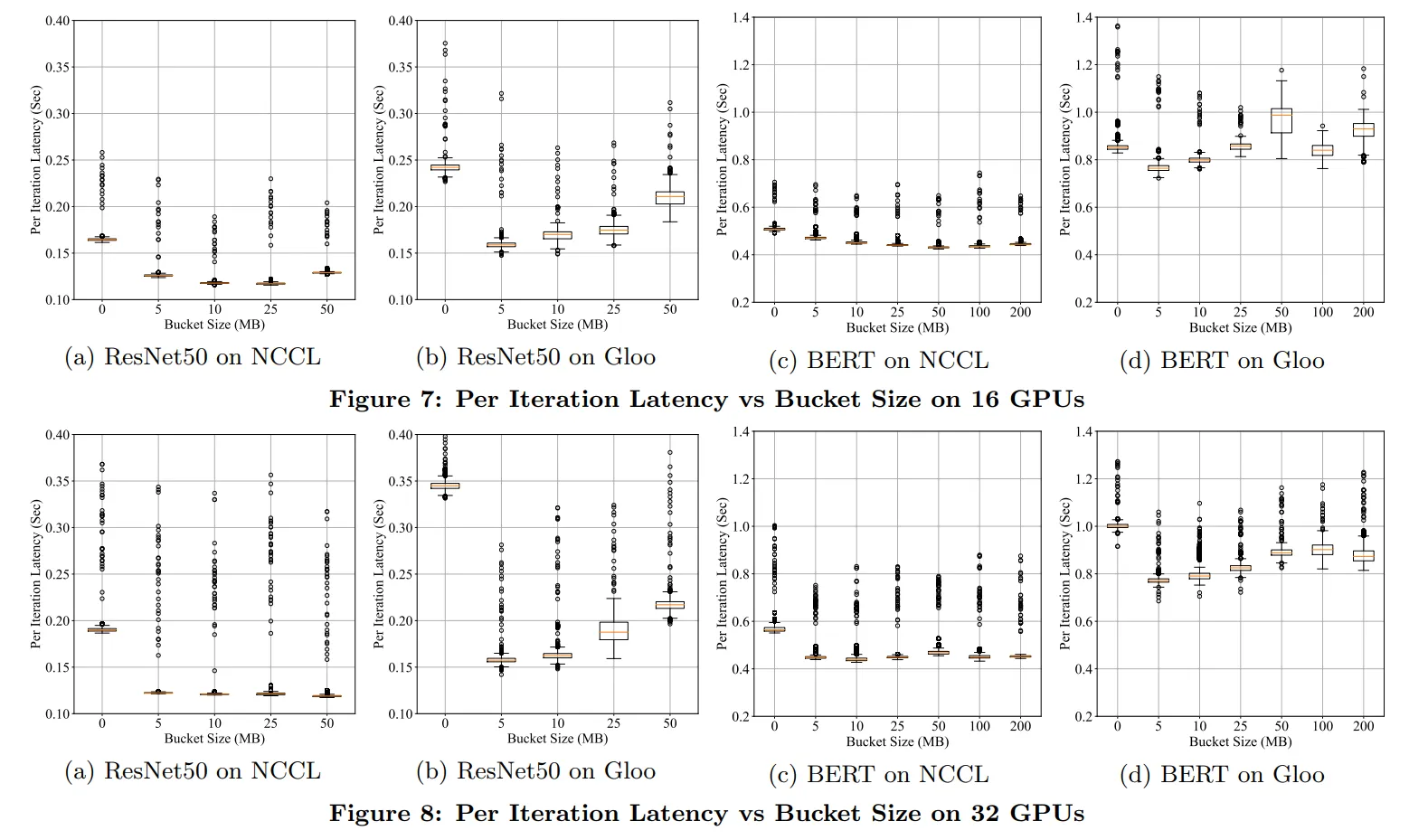
桶规约:默认 bucket size 为 25M,实践中需要实验得到最佳大小
全局未使用参数:在 CPU 上创建 bitmap 来保存本地没有使用的参数信息,并通过一个额外的allreduce得到 global bitmap

实验
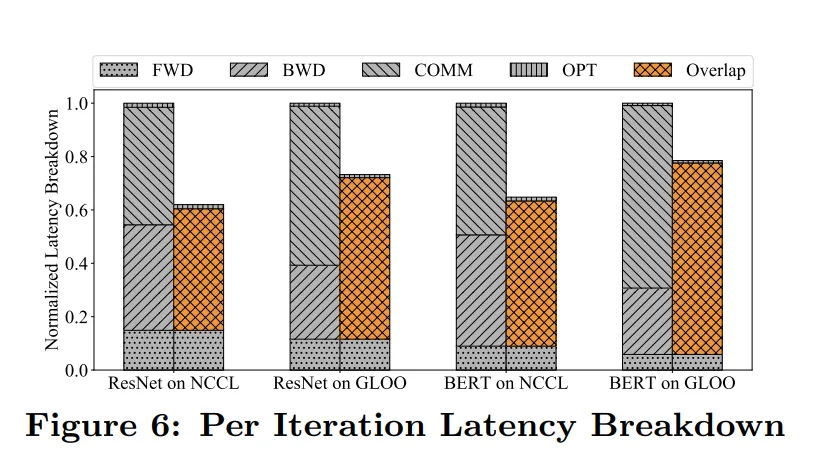
通过 Latency Breakdown(对训练过程中不同阶段的延迟进行细分和分析)比较了不同模型、使用不同 backend、有无通信和训练的 overlap,得到反向传播是最耗时是阶段,AllReduce 就是在这一阶段中,仍然需要优化通信效率
下图实验了不同 bucket size
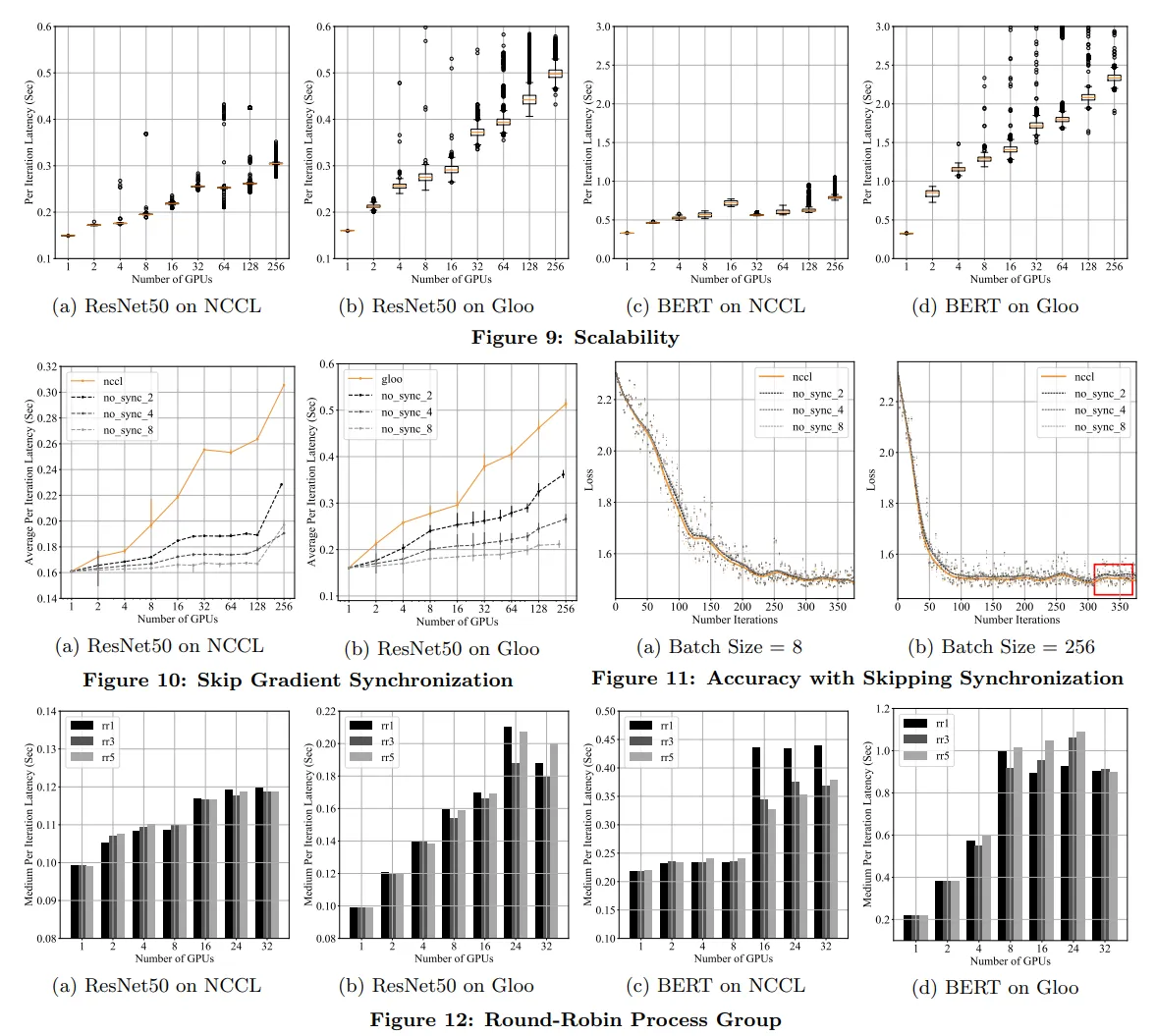
DDP通过使用多个round-robin(轮询调度)进程组从而充分利用带宽。下图实验比较了使用不同数量进程组对 latency 的影响
讨论
通信后端:NCCL 优于 GLOO
bucket size:大小随着模型的增大而增大
资源分配:用 NCCL 时建议把同一台机器上的所有进程都放到同一个进程组中
改进
- 梯度顺序预测:使用 autograd hook 记录 backward 的顺序,并相应地更新 bucket mapping 中的对应参数
- Layer dropping:在forward的过程中随机 drop 掉几层网络,加速训练的同时避免过拟合,与此同时相应修改 parameter-to-bucket mapping,或从 bucket 层面 drop 网络层
- 梯度压缩:只通信需要高精度的梯度