摘要
最近忙实习去了,断更大半年。整理了一下论文,有十几篇没读,后面有时间慢慢更。
这篇论文主要工作是对 TensorFlow 框架 API 的重写,使用 ring-allreduce 和 broadcast 方法,进行数据并行。
paper: https://arxiv.org/abs/1802.05799
code: https://github.com/uber/horovod
背景
训练时的 GPU 通信耗时过大
当时分布式训练加速需要修改大量代码,成本过高
TensorFlow 不足
TensorFlow 的分布式引入了许多复杂的概念和 API,使用成本变高,很难发现修复隐藏的 bug
使用 128 张 GPU 进行大规模训练时,通信与计算占比相当,可扩展性差
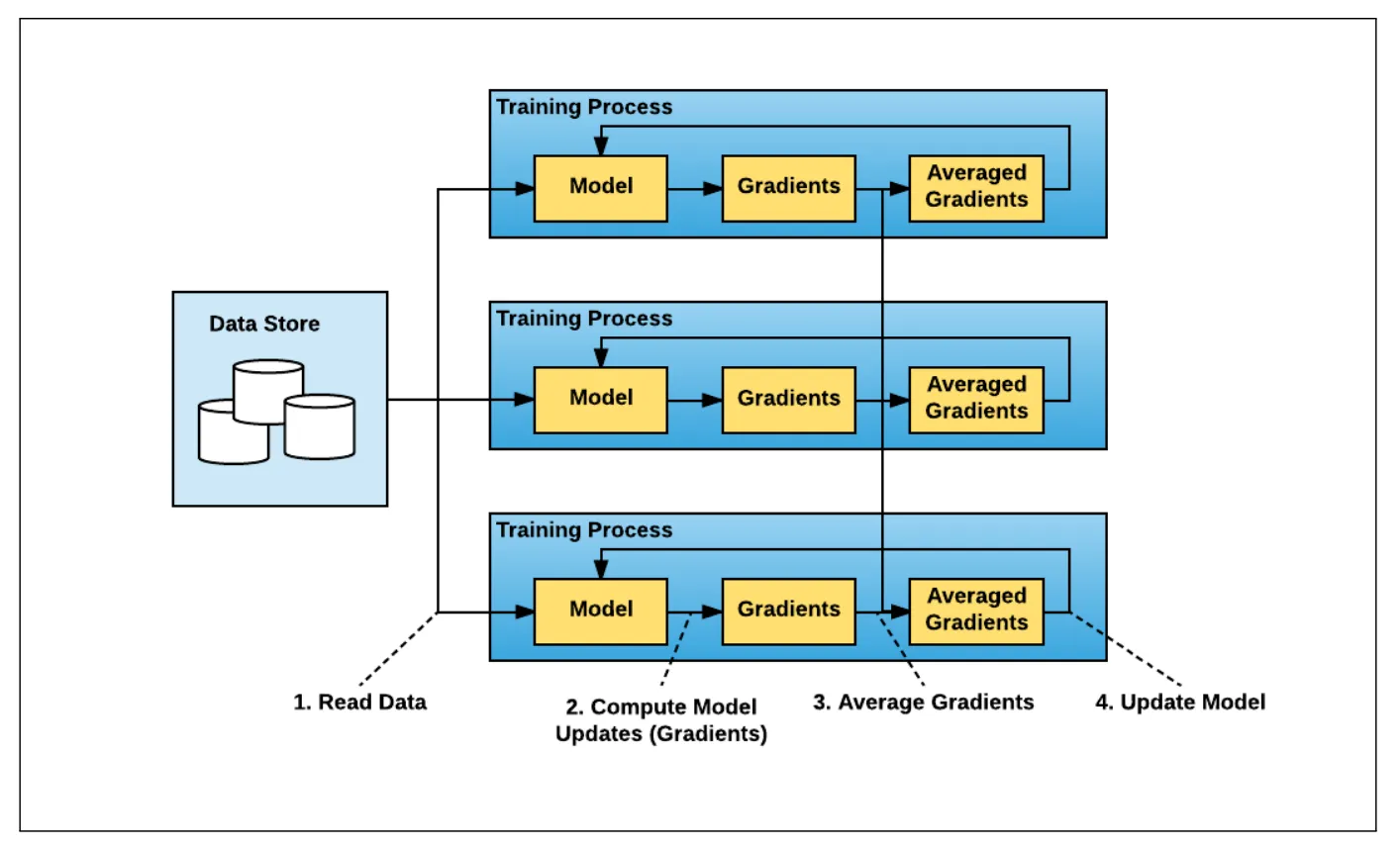
Facebook 首次提出数据并行,在多个节点上并行拆分数据来训练。不同批次数据的梯度在每个节点上单独计算,之后收集梯度求平均后广播到每个节点上,以保证每个节点中的模型副本参数一致
Leveraging a different type of algorithm
TensorFlow 通过指定一个进程为 worker(工作进程) 或 parameter servers(参数服务器)

worker 负责前反向传播,发送计算得到的梯度,接收平均后的梯度和数据
有两个难点:
- worker 和 parameter servers 比例难以确定,太少的 parameter servers 会导致计算饱和,太多的 parameter servers 会导致通信饱和
- 学习曲线陡峭,大量代码重构
ring allreduce 的提出解决了这个问题

N个节点中的每个节点与其两个对等节点进行通信,共进行了2 * (N - 1)次通信,节点发送和接收数据缓冲区的块。在第一次(N - 1)次迭代时,接收到的值会被添加到节点缓冲区中的值中。在第二次(N - 1)次迭代时,接
收到的值将替换节点缓冲区中的值
Horovod
做了如下工作
- 将百度的 TensorFlow ring-allreduce 算法的实现转化为一个独立的 Python 包,命名为 Horovod
- 使用 NCCL 库实现了 TensorFlow ring-allreduce,并优化了性能
- 添加了对单机多卡的支持
- 改进了 API,添加 broadcast 操作,仅需 4 步即可使用 Horovod
使用方法
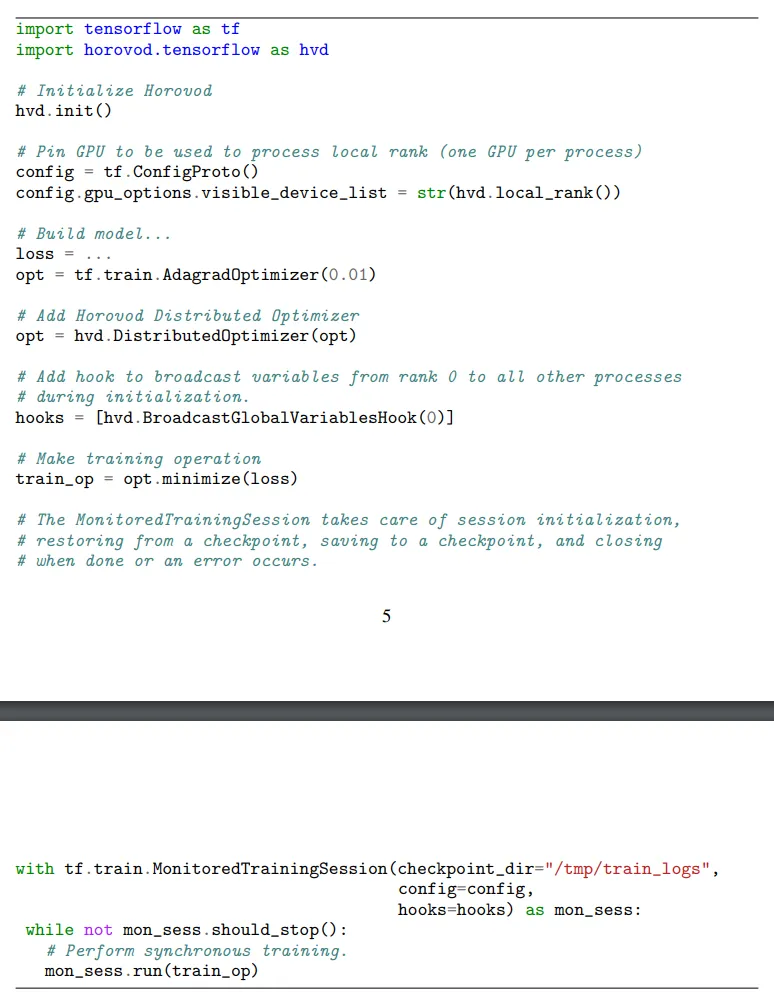
下面代码使用 mpirun 命令在 4 张卡的 4 个 server 上运行 train.py,支持 TensorFlow 和 Keras
1 | mpirun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py |
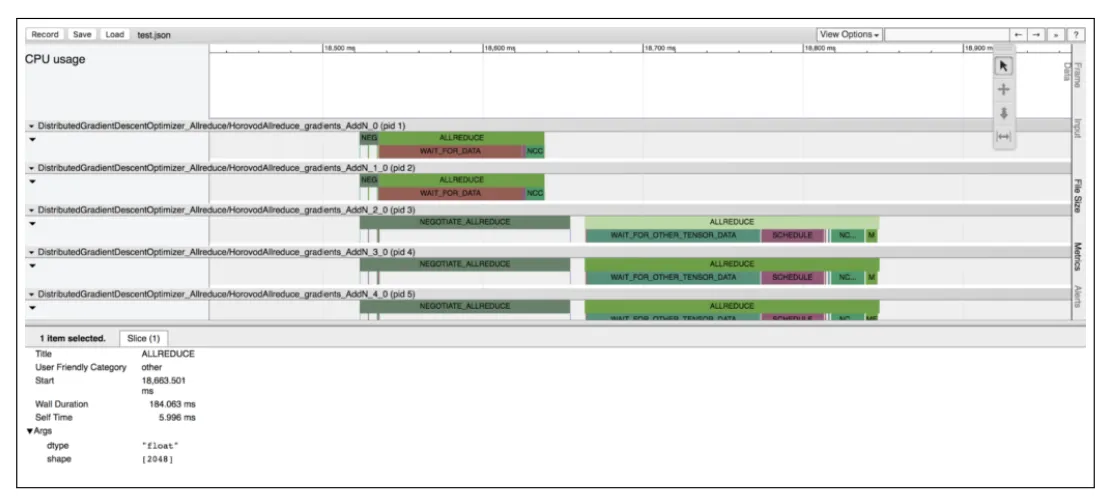
Horovod Timeline
TensorFlow 和 CUDA Profiler 不足:只能显示单个 server 的 Profiler,需要用户手动交叉比对
改进:如下图所示,设置环境变量,就可以查看训练时每个节点在每个时间步骤中的具体操作,并且兼容 chrome://tracing
Tensor Fusion
观察 Profiler 时发现不足:大 Tensor 可以很好地利用带宽,但是小 Tensor 的 ring-allreduce 会影响效率
改进:
- 整理要 allreduce 的 Tensor,分配到匹配的同数据类型的 buffer,如果没能成功分配,就创建一个 fusion buffer,默认为 64 MB;
- 将 Tensor 拷贝到 buffer,对 fusion buffer 执行 broadcast,再将 Tensor 拷贝出来。重复上述步骤;
对比得到 65% 的性能提升
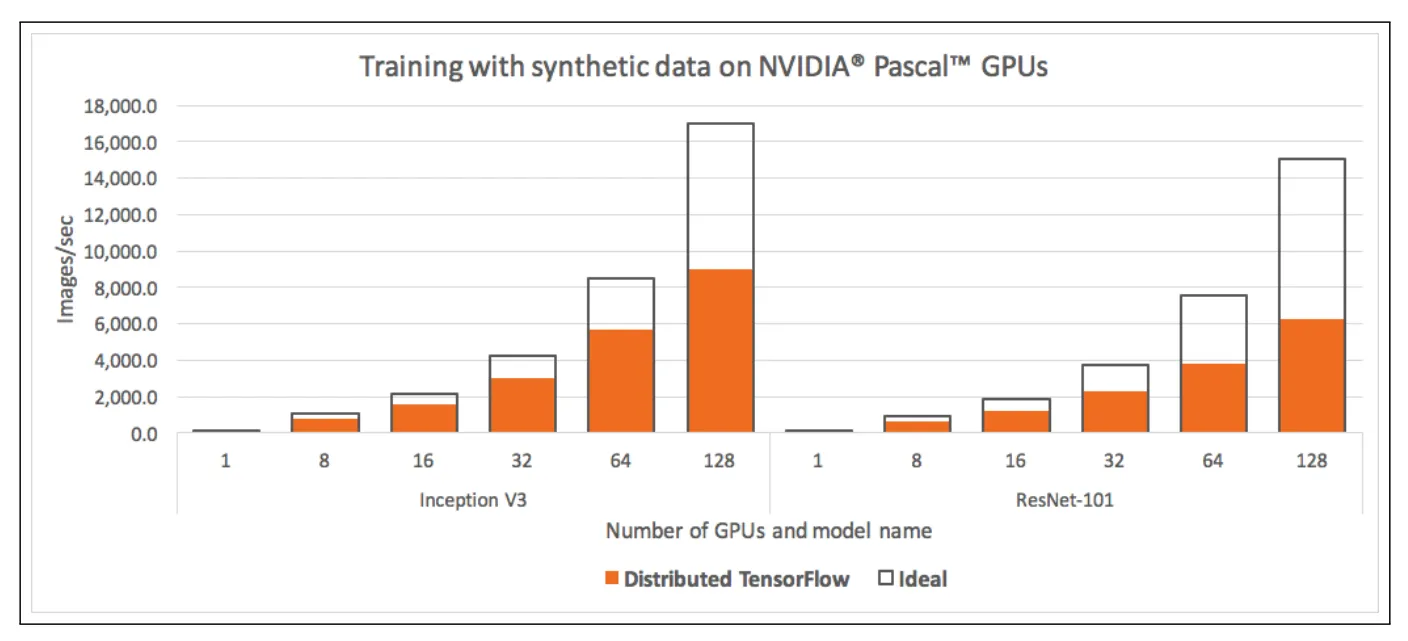
Horovod Benchmarks
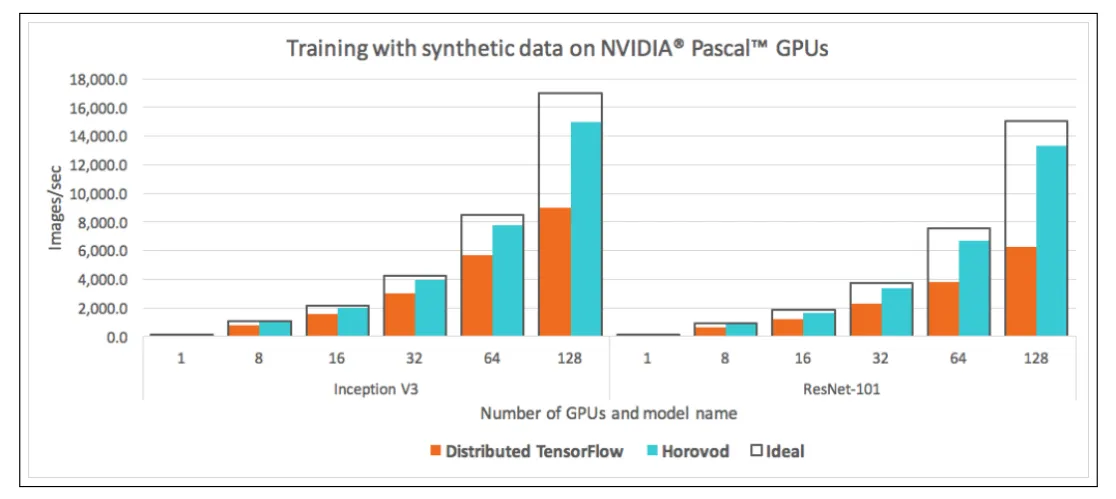
上图所示,使用 Inception V3和ResNet-101模型进行实验,Horovod 相比 TensorFlow 性能提升了 88%
使用 RDMA 与 TCP 进行基准测试。在 Inception V3和 ResNet-101 模型上,RDMA 并没有显著提高性能,只比 TCP 网络多了 3% 到 4% 的增长

但是在 VGG-16 模型上,使用RDMA网络性能提高了30%。可以解释为 VGG-16 模型具有大量的参数,结合其较少的层数,使得通信成为关键路径,使得网络成为瓶颈
改进
- 使 MPI 安装使用更方便
- 着重研究如何调整模型的超参以提高准确率
- 开发更多大模型训练示例